What Is Trust in E-E-A-T? The Foundation Google Cares About Most
AI Summary
What is the Trust signal in E-E-A-T? Trust is the T in E-E-A-T and the factor Google has explicitly named the most important of the four. It evaluates whether a site can be relied on, covering accuracy, transparency, security, business legitimacy, and freedom from deception.
What it is and who it is for: Trust is the foundation Google cares about above the other three letters. It matters most for any site whose content has the potential to affect a reader’s wellbeing, finances, safety, or major life decisions. The framework calls these YMYL topics, and Trust scrutiny is highest there.
The rule: Without Trust, the other three letters of E-E-A-T do not save a site. A page with full Experience, full Expertise, and full Authoritativeness still fails the framework if Trust is absent. Google’s own guidance names Trust as the most important factor in the family.
Table of Contents
- What Trust Means in E-E-A-T
- Why Google Names Trust the Most Important Factor
- How Google Measures Trust
- Accuracy as the Substrate of Trust
- Transparency Signals: About, Contact, and Editorial Policy
- Security and Technical Trust Signals
- YMYL Topics and Elevated Trust Scrutiny
- Building Trust From Zero
- How Trust Fails: The Common Patterns
- Verdict
What Trust Means in E-E-A-T
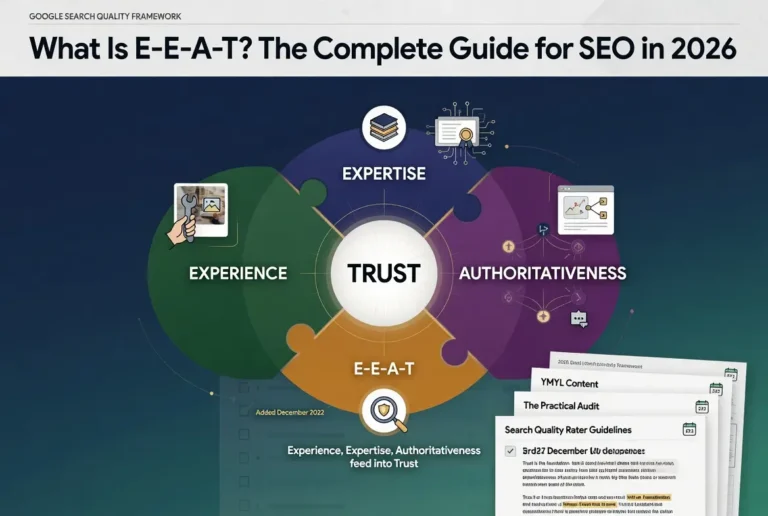
Trust is the fourth letter of E-E-A-T and the one Google has been most explicit about prioritizing. The other three letters describe what a site or creator brings to a topic. Trust describes whether the broader system, including readers, the algorithm, and the web at large, can rely on what the site says and does.
The official framing comes directly from Google’s Search Quality Rater Guidelines, which state that Trust is the most important member of the E-E-A-T family. The diagram in the guidelines puts Trust at the center of the framework rather than treating it as one quadrant among four. Experience, Expertise, and Authoritativeness all feed into Trust, and a site that fails on Trust fails the framework as a whole regardless of how strong it scores on the other three signals.
The dimension is broad on purpose. Trust covers whether the page is accurate. Whether the site is transparent about who runs it. Whether the technical infrastructure is secure. Whether the business behind the site is legitimate. Whether the content is free from deception or manipulation. Each of these has its own evaluation logic, but they aggregate into a single judgment about reliability.
The shorthand version: Trust is the question of whether a reasonable person, knowing what the site is and how it operates, would feel safe using it for the purpose the page implies. A medical page that fails this test fails harder than a recipe page, because the cost of being wrong is higher. The framework adjusts.
For the broader cluster context, the Pillar guide on E-E-A-T covers how Trust integrates with the other three signals. The sibling articles on Experience, Expertise, and Authoritativeness cover the first three letters.
Why Google Names Trust the Most Important Factor
Most discussions of E-E-A-T treat the four letters as parallel signals. The official framework does not. The Quality Rater Guidelines elevate Trust above the others and frame the relationship as hierarchical. Experience, Expertise, and Authoritativeness exist to support Trust. They are inputs. Trust is the output that matters for whether the page should be surfaced.
The reasoning behind this elevation is straightforward when stated directly. Google’s product is the search results page. The product fails when users land on pages that mislead them, harm them, or do not reliably deliver what the page promises. The other three letters of E-E-A-T are useful diagnostic signals, but the question Google’s systems are ultimately optimizing for is whether the page is reliable. Trust is the dimension that names that question explicitly.
The hierarchy has a practical implication that operators frequently miss. A page can demonstrate full Experience through first-person testing photographs, full Expertise through verified credentials, and full Authoritativeness through editorial citations from recognized voices in the field, and still fail the framework if the page is making inaccurate claims, hiding ownership, lacking basic security, or operating as part of a deceptive site structure. The other three signals do not save the page. Trust is the gate.
The reverse case is rarer but instructive. A page can have modest Experience, average Expertise, and limited Authoritativeness and still pass the framework if the Trust signals are strong. Honesty about what the page is, accuracy in what it claims, transparency about the site’s operations, and reasonable security infrastructure can carry a page that lacks the other dimensions. The compounding effect runs through Trust.
How Google Measures Trust
The same caveat that applies to the other three letters applies here. E-E-A-T is not a direct ranking factor. The Quality Rater Guidelines describe a framework used by human evaluators whose feedback trains the algorithms over time. Google’s systems cannot directly measure Trust the way a human rater can. They measure proxies for Trust.
The proxies break into four broad categories.
The first is accuracy signals. Whether the factual claims on the page align with what other authoritative sources say. Whether the page hedges or asserts in proportion to the evidence. Whether the citations link to sources that actually support the claims being made. Whether the page corrects itself when errors are surfaced. Accuracy proxies are difficult to measure directly, but Google’s systems have grown more capable at flagging pages where the asserted claims diverge from the consensus of authoritative coverage on the same topic.
The second is transparency signals. Whether the site identifies who is responsible for the content. Whether contact information is present and complete. Whether the editorial process is explained. Whether the funding model is disclosed. Whether the relationships between the site and the content are clear, including affiliate disclosures, sponsored content disclosures, and any ownership relationships that affect what the site publishes. Transparency proxies are easier to measure because they are surface features of the site.
The third is technical trust signals. Whether the site uses HTTPS. Whether the domain has been registered for a meaningful length of time rather than weeks. Whether the hosting infrastructure is stable. Whether security headers are implemented. Whether the site has been compromised in ways the systems can detect. Technical trust signals are not the deepest layer of the Trust framework, but they are the easiest to measure and they function as a baseline filter.
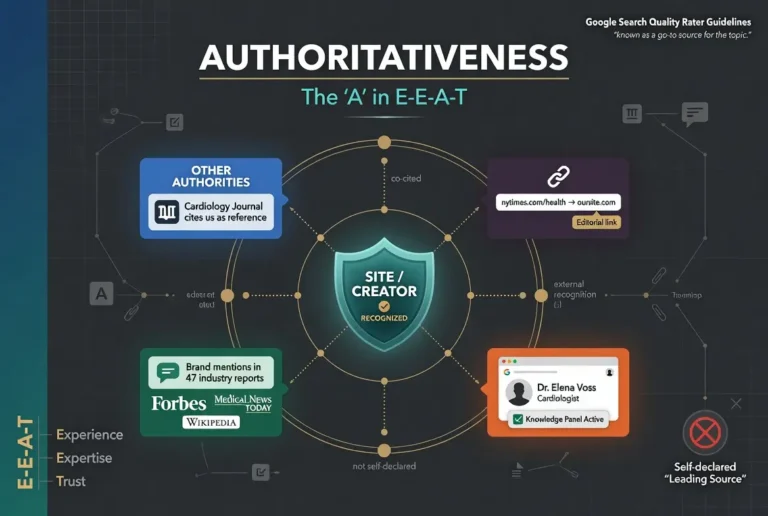
The fourth is reputation signals. Whether the broader web treats the site as legitimate. Whether reviews of the site or the business behind it are positive. Whether the site appears on lists of known scam operations or deceptive sites. Whether journalists, researchers, and other authoritative voices have written about the site in ways that confirm its legitimacy. Reputation signals connect Trust back to Authoritativeness, which is part of why the four letters reinforce each other in the official framework.
The implication for operators is that all four categories matter, and Trust failures in any single category propagate through the framework. A site can have strong accuracy and transparency and still fail Trust through technical security gaps. A site can have strong technical infrastructure and still fail Trust through inaccurate claims that cite sources which do not support the assertions being made.
Accuracy as the Substrate of Trust
Of the four Trust proxy categories, accuracy is the one most directly tied to whether the page should rank. Inaccurate content is the failure mode the entire framework is built to surface and demote. The other three categories matter, but they exist downstream of the question of whether the page is telling the truth.
The operational definition of accuracy in the Trust context is more specific than the casual usage of the word. A page is accurate when its factual claims align with the established consensus of authoritative coverage on the topic, when its hedges and assertions match the actual evidence available, and when its citations point to sources that support the claims being made rather than decorative references that do not actually verify the assertion.
The first failure mode is the assertion-citation gap. A page makes a strong claim, links to a source, and the source does not actually support the claim being made. The link is decorative. Readers who follow the citation discover the gap. Quality raters who follow the citation flag the page. Over time, Google’s systems improve at detecting this pattern through proxies. The fix is straightforward in principle. Every assertion should link to a source that genuinely supports it, and assertions that lack supporting sources should be hedged or removed.
The second failure mode is the consensus departure without justification. A page makes claims that diverge from what authoritative sources say on the topic, and the divergence is not explained. The page may be correct and the consensus may be wrong, but the page does not engage with the discrepancy. Google’s framework treats this as a Trust failure even when the page’s claim is technically defensible, because the page has not given readers the context to evaluate the claim against what they will find elsewhere.
The third failure mode is the dated claim. A page makes claims that were accurate when published but have since become wrong, and the page has not been updated. This is a softer failure than the first two, but it accumulates. A site with many dated pages signals an editorial process that does not maintain accuracy over time. The fix is consistent content review on a schedule that matches the volatility of the topics being covered.
For more on the connection between accuracy and the broader content production discipline, the Content discipline covers the operational architecture.
Transparency Signals: About, Contact, and Editorial Policy
Transparency is the most operationally addressable Trust category for any site. The signals are surface features that can be implemented in a single afternoon, and the absence of any one of them is a direct flag for both quality raters and the algorithmic proxies that approximate their judgment.
The baseline transparency stack has three components. An About page that identifies who runs the site and what their qualifications are for covering the topics published. A Contact page that provides at least one method of reaching the site beyond a comment form. An editorial policy or methodology page that explains how content is produced, fact-checked, and updated. The first two have been baseline for years. The third has become more important as AI-generated content has flooded the web and readers have started expecting explicit information about how the content they read came to exist.
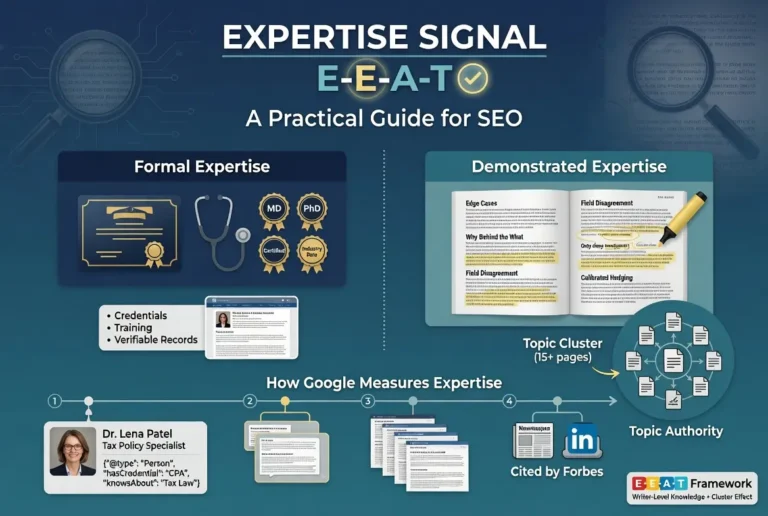
The depth of the transparency stack scales with the topic. A recipe site can pass the framework with a basic About page and contact form. A medical site needs author bylines on every page, named medical reviewers, an editorial policy that explains the review process, disclosed conflicts of interest for any contributor with industry relationships, and ideally a corrections policy that names how errors are surfaced and fixed. The framework adjusts to the topic.
One detail that operators frequently miss. The transparency information needs to be machine-readable as well as human-readable. The Schema.org Person and Organization types include properties that map directly onto the transparency signals, and consistent use of these schemas helps Google’s systems align the published transparency information with what the broader web is saying about the site.
The single most common transparency failure on new sites is the missing or boilerplate About page. A site that publishes content without identifying who is responsible for it has skipped the foundation of the transparency stack. The fix is to write a real About page that names the people involved, their qualifications, and their relationship to the topics being covered. Generic About pages copied from templates do not produce the signal because they are easy for systems to detect and they tell readers nothing.
Security and Technical Trust Signals
The technical layer of Trust is the easiest to address and the most binary in its evaluation. Sites either implement the baseline or they do not, and the systems can measure each component directly.
The baseline starts with HTTPS. A site running on plain HTTP fails the technical Trust filter at the first measurement. The remediation is the SSL certificate, which is free through Let’s Encrypt and trivially easy to implement on any modern hosting environment. Sites still running HTTP in 2026 are signaling either neglect or an inability to perform basic web operations, and the framework treats both interpretations as a Trust failure.
Beyond HTTPS, the technical Trust stack includes a few more signals. Properly configured security headers including HSTS, Content-Security-Policy, and X-Content-Type-Options. A privacy policy and cookie policy that match what the site actually does with visitor data. Compliance with applicable privacy regulations including GDPR for European visitors and CCPA for California visitors. Domain registration that has been in place for a meaningful length of time rather than days or weeks. Hosting infrastructure that does not produce frequent downtime or security incidents.
The honest read on technical Trust signals is that they function as a baseline filter rather than a competitive differentiator. Implementing them does not make a site stand out. Failing to implement them eliminates the site from consideration before the more substantive Trust signals are even evaluated. The investment is small and the absence is consequential.
One area where technical Trust signals connect directly to ranking is the relationship between site security incidents and search visibility. Sites that get compromised, particularly through malware injections or hijacked redirects, frequently lose substantial search visibility before the compromise is detected. Google’s spam policies address hacked content explicitly, and recovery from a security incident often takes weeks or months even after the underlying issue is fixed. The implication is that security investment is not just a Trust signal in the framework sense. It is a direct operational protection against ranking loss.
YMYL Topics and Elevated Trust Scrutiny
The Trust framework adjusts based on the topic, and the most important adjustment happens for content classified as YMYL. The acronym stands for Your Money or Your Life, and it covers topics where inaccurate or misleading content can cause real harm to readers. Health, finance, legal, safety, civics, and major life decisions all fall under the YMYL umbrella.
The adjustment is not subtle. Trust signals that would pass the framework on a recipe site fail the framework on a medical site. The reasoning is proportional. The cost of an inaccurate recipe is a bad meal. The cost of inaccurate medical advice is potentially someone’s health. The framework treats these as different evaluations because the consequences of getting it wrong are different.
The operational implication for sites publishing YMYL content is that the baseline Trust stack is not enough. The transparency layer needs to include named author credentials, named expert reviewers where applicable, explicit editorial methodology, and clear corrections policies. The accuracy layer needs to engage with the consensus of authoritative coverage rather than asserting independent positions without justification. The security layer needs to handle visitor data with the care that the topic implies. None of these are optional for YMYL content if the goal is to pass the framework.
The category of who counts as an authoritative source on YMYL topics also tightens. A site covering general home improvement can pass the framework with practical writers and demonstrated experience. A site covering medical topics needs medical professionals reviewing the content and making the medical claims, not lay writers researching from secondary sources. The Trust framework does not treat these as equivalent regardless of how well the lay writer researches.
One worth flagging. YMYL classification is not a binary at the site level. Individual pages within a broader site can carry YMYL implications even when the site as a whole is not primarily YMYL. A general lifestyle site that publishes a single article on prescription medication is being evaluated under YMYL standards for that page even though the rest of the site is not. The page-level evaluation matters.
For the structural side of how Trust integrates with the broader Credibility infrastructure on YMYL-relevant sites, the Credibility discipline covers the operational architecture.
Building Trust From Zero
The hardest case for Trust is the new site with no track record. Several Trust signals depend on history, including reputation, domain age, and the accumulated record of accuracy over time. None of these are available on day one. The question becomes how to establish the foundation that earns Trust as the site matures.
The work breaks into four stages. The first three are addressable immediately. The fourth requires patience.
Stage one is the technical baseline. HTTPS, security headers, privacy policy, GDPR/CCPA compliance, stable hosting. Done in the first week of the site’s existence. Not negotiable. The cost is low and the absence is disqualifying.
Stage two is the transparency stack. Real About page that names who runs the site and what their qualifications are. Working contact methods. Editorial policy that explains how content is produced. Author bylines on every page where the topic implies authorship matters. Schema markup that makes the transparency information machine-readable. Done in the first month.
Stage three is the accuracy discipline. Every assertion in published content should link to a source that genuinely supports it. Hedging should match the evidence. Consensus departures should be explained. Updates and corrections should be visible rather than silent edits. This stage continues for the life of the site, but the discipline starts with the first published article.
Stage four is the reputation accumulation. This is the slow one. Reviews of the site or the business behind it accumulate over time. Editorial mentions accumulate over time. The track record of accuracy accumulates over time. None of this can be manufactured, and operators who try to manufacture reputation through fake reviews or coordinated mention campaigns produce signals that the framework increasingly identifies and discounts. The honest path is to do the substantive work and let the reputation follow.
The compounding effect is real. A site that holds the discipline for six months has a fundamentally different Trust profile than a site that lapses on accuracy or transparency. The trajectory matters more than the snapshot.
How Trust Fails: The Common Patterns
The most common Trust failures are not exotic. They are predictable patterns that show up across new sites, established sites that have grown careless, and sites that were built primarily for search engines rather than readers.
The first common failure is the missing or generic About page. The site is producing content but does not identify who is responsible for it. The transparency layer has a hole at the foundation. Readers who want to evaluate the source cannot. Quality raters who reach the page flag it. Algorithmic proxies that approximate the rater judgment register the absence.
The second common failure is the citation theater. The page links to authoritative sources, but the linked sources do not actually support the claims being made. The links are decorative. The pattern is detectable because following the citations reveals the gap. The fix is the discipline of linking to sources that genuinely support the assertion rather than treating links as ornaments that prove the page did research.
The third common failure is the security gap. The site is running on HTTPS, but other security signals are missing. Headers are not configured. Privacy policy does not match what the site does with visitor data. Cookie consent is absent for visitors in regions that require it. The technical Trust baseline has been partially implemented in a way that signals neither commitment to security nor neglect, just the surface gesture of compliance without the underlying work.
The fourth common failure is the YMYL miscalibration. The site is publishing content with YMYL implications without adjusting the Trust stack to match. Lay writers researching medical topics rather than medical professionals writing them. Generic editorial policies that do not engage with the elevated scrutiny the topic implies. Affiliate-driven content recommending products in YMYL categories without the credentialing the topic requires. The page-level evaluation surfaces these miscalibrations even when the rest of the site passes the framework.
The fifth common failure is the reputation manipulation attempt. Fake reviews. Coordinated mention campaigns. Self-placed bylines across thin sites. The pattern produces surface features of Trust without producing the underlying recognition. Quality raters identify the pattern faster than algorithmic proxies, and the rater feedback over time trains the systems to discount the engineered signals. The fix is to do the substantive work and earn the reputation honestly. The shortcut path is increasingly unrewarded.
The diagnostic question for any Trust-building tactic is whether the tactic produces the underlying signal or just the surface feature. Surface features without underlying signals fail the framework at the rater level and increasingly at the algorithmic level. Substantive work that produces both the signal and the surface feature scales.
Verdict
Trust is the foundation of E-E-A-T and the factor Google has explicitly named the most important. The framework treats Experience, Expertise, and Authoritativeness as inputs that feed Trust, and a site that fails Trust fails the framework regardless of how strong it scores on the other three signals. The hierarchy is direct in the official guidance.
The proxy signals Google’s systems use include accuracy, transparency, technical security, and reputation. All four reinforce each other, and Trust failures in any single category propagate through the framework. The implication for operators is that Trust is the dimension that requires investment across the broadest set of operational areas, including content production, site infrastructure, business legitimacy, and editorial discipline over time.
For YMYL topics, Trust scrutiny is elevated, and the baseline that passes the framework on general topics fails the framework on health, finance, legal, safety, and civic content. The framework adjusts to the cost of being wrong. The content production discipline has to adjust with it.
The practical sequence for building Trust from zero is the four-stage progression. Lock the technical baseline immediately. Build the transparency stack in the first month. Hold the accuracy discipline as a permanent commitment from the first published article forward. Let the reputation accumulate over time as a function of the substantive work, not through manufactured shortcuts.
For the integration of Trust with the other three letters as a system rather than four independent signals, the Pillar piece covers the framework as a whole. The sibling articles on Experience, Expertise, and Authoritativeness cover the inputs that feed into Trust.
Frequently Asked Questions
Why does Google call Trust the most important factor in E-E-A-T?
The Search Quality Rater Guidelines state explicitly that Trust is the most important member of the E-E-A-T family. The framework diagram puts Trust at the center, with Experience, Expertise, and Authoritativeness functioning as inputs that feed into the Trust judgment. A page that fails on Trust fails the framework regardless of how strong the other three signals are.
Is Trust a direct ranking factor?
No. E-E-A-T as a whole is not a direct ranking factor. It is a quality framework used by human raters whose feedback trains Google’s ranking systems over time. The proxy signals Google’s algorithms use to estimate Trust, including accuracy, transparency, technical security, and reputation, do influence rankings through other mechanisms.
What is the difference between Trust and Authoritativeness?
Authoritativeness asks whether the broader web treats a site or creator as a recognized source on a topic. Trust asks whether the site can be relied on overall, covering accuracy, transparency, security, and freedom from deception. A site can have Authoritativeness without Trust if the recognition was earned through manipulation rather than substantive work, and a site can have Trust without full Authoritativeness if it is a newer site doing the work honestly.
What does YMYL mean and how does it affect Trust evaluation?
YMYL stands for Your Money or Your Life and covers topics where inaccurate content can harm readers, including health, finance, legal, safety, and major life decisions. Trust scrutiny is elevated for YMYL content, and the baseline that passes the framework on general topics fails on YMYL topics. Author credentials, expert review, and editorial methodology requirements all tighten for YMYL content.
What is the most common Trust failure on new sites?
The missing or generic About page. Sites publish content without identifying who is responsible for it, which leaves a hole in the transparency layer at the foundation. The fix is to write a real About page that names the people involved, their qualifications, and their relationship to the topics being covered. Generic or boilerplate About pages do not produce the signal.
How long does it take to build Trust from zero?
The technical baseline can be locked in the first week. The transparency stack can be built in the first month. The accuracy discipline starts with the first published article and continues for the life of the site. The reputation layer accumulates over time and cannot be rushed without producing manufactured signals that the framework increasingly identifies and discounts.
Does HTTPS alone satisfy the technical Trust requirement?
No. HTTPS is the baseline that prevents the site from being eliminated at the first filter, but the full technical Trust stack includes properly configured security headers, a privacy policy that matches what the site does with visitor data, applicable regulatory compliance, and stable hosting infrastructure. HTTPS alone is necessary but not sufficient.
Can a site recover Trust after a security compromise?
Yes, but recovery typically takes weeks or months even after the underlying issue is fixed. Sites that get compromised through malware injections or hijacked redirects frequently lose substantial search visibility before the compromise is detected, and Google’s systems take time to re-evaluate the site after remediation. The implication is that security investment functions as both a Trust signal and direct operational protection against ranking loss.