What Is E-E-A-T? The Complete Guide for SEO in 2026
AI Summary
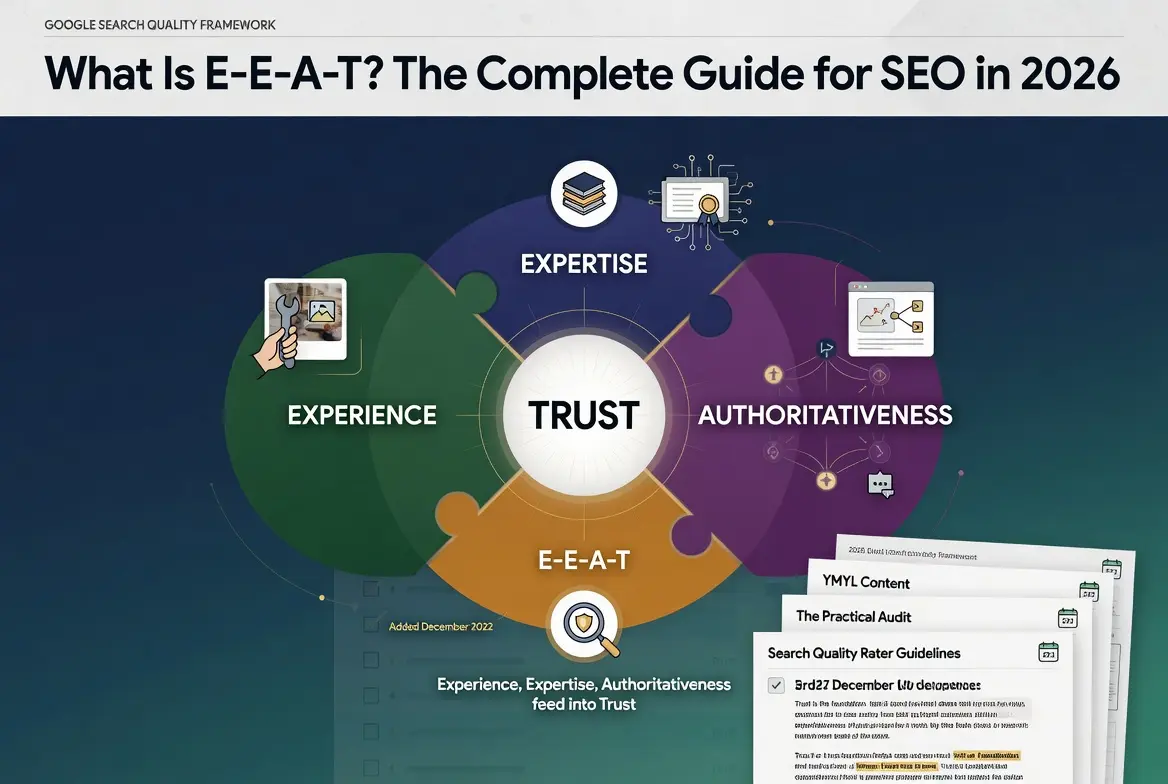
What is E-E-A-T? E-E-A-T stands for Experience, Expertise, Authoritativeness, and Trust. It is the quality framework from Google’s Search Quality Rater Guidelines that describes the qualities Google’s algorithms are trying to surface in search results.
What it is and who it is for: E-E-A-T is the operating definition of content quality that Google’s human raters use to evaluate pages, and the rater feedback trains the ranking systems over time. It matters for any site whose long-term visibility depends on being seen as a quality source on its topics.
The rule: Trust is the most important of the four letters, and Google has stated this directly. Experience, Expertise, and Authoritativeness function as inputs that feed into Trust. A site that fails on Trust fails the framework regardless of how strong it scores on the other three signals.
Table of Contents
The Four Letters of Modern SEO
E-E-A-T is the framework Google uses to describe what content quality actually means in operational terms. The acronym expands to Experience, Expertise, Authoritativeness, and Trust, and it lives inside the Search Quality Rater Guidelines, the document Google’s human evaluators use when they grade search results. The rater feedback trains the algorithms over time, which is how a framework that is not technically a ranking factor ends up shaping which pages rank.
The framework started as E-A-T in 2014, with three letters covering Expertise, Authoritativeness, and Trust. The fourth letter, Experience, was added in December 2022 to capture a quality the original framing missed. The world had filled with credentialed writers reciting research they had not lived through, and the framework needed a way to recognize first-hand contact with the topic as distinct from credentialed knowledge about the topic.
Most discussions of E-E-A-T treat the four letters as parallel signals of equal weight. The official framework does not. Google has been explicit that Trust is the most important of the four, and the framework diagram in the rater guidelines puts Trust at the center with the other three feeding into it. Experience, Expertise, and Authoritativeness function as inputs. Trust is the output that determines whether the page should be surfaced. A page can demonstrate full Experience, full Expertise, and full Authoritativeness and still fail the framework if Trust is absent. The hierarchy is direct in the official guidance.
The practical implication for any site trying to build long-term search visibility is that the four letters need to be developed together, not as independent checklists. Investment in one signal without the others produces a fragile profile. A site can be strong on Experience and weak on Trust if it has lived experience but lacks transparency or accuracy. A site can be strong on Authoritativeness and weak on Experience if it has earned recognition through theoretical coverage but no first-hand testing. The configurations that scale are the ones where all four letters reinforce each other.
This pillar covers each letter in summary and ties them together as a system. The deep-dives on each signal live in the four sibling articles linked from the sections below. The deeper context on the broader content production discipline that supports E-E-A-T lives at the Content discipline page, and the operational architecture for building Trust-relevant infrastructure lives at the Credibility discipline page.
Experience: The New E
Experience is the letter Google added in December 2022, and the addition was deliberate. The framework before that point recognized credentialed knowledge through Expertise but had no operational way to recognize first-hand contact with a topic as a separate signal. A board-certified cardiologist who had never seen a patient outside of training was treated the same as a cardiologist with thirty years of clinical practice. The 2022 addition closed that gap.
The operational definition of Experience is whether the writer has personally lived through the topic they are writing about. The signal is observable in content through specific markers. First-person testing photographs that show the actual product or process being used. Anecdotes that include details only someone who had been there would include. Hedging that reflects the writer’s actual confidence rather than the confidence the writing position implies. The pattern of failure modes the writer expects to encounter, which only emerges from having encountered them.
The distinction between Experience and Expertise is the one most discussions of E-E-A-T blur. Expertise is built through training, credentials, and demonstrated knowledge. Experience is built through first-hand contact. The two are related but not interchangeable. A writer can have full Expertise without Experience, and a writer can have full Experience without formal Expertise. The strongest configurations have both, and the framework treats those as separate evaluations because the signals come from different sources.
The cardiology example clarifies the gap. A medical student who completes their training and begins writing patient education content has full Expertise from the moment they start. They have the credentials, the framework knowledge, and the demonstrated capacity to discuss the topic accurately. They do not yet have Experience. The Experience develops over the years of clinical practice, where they encounter the patterns that do not appear in textbooks and develop the calibrated confidence that comes from having been wrong and corrected by reality.
The reverse case is also instructive. A patient who has lived with a chronic condition for fifteen years has full Experience with the condition. They know the daily texture of it, the failure modes, the small things that work and the small things that do not. They do not have Expertise in the formal sense. The framework recognizes both as real, and a site that combines patient-Experience writing with credentialed-Expertise medical review produces a stronger profile than either signal alone.
For the deeper treatment of how Experience signals are demonstrated in content, how to distinguish authentic Experience from manufactured Experience, and the practical patterns operators can use to build the signal deliberately, the tier article on Experience covers the full operational guide.
Expertise: Beyond Credentials
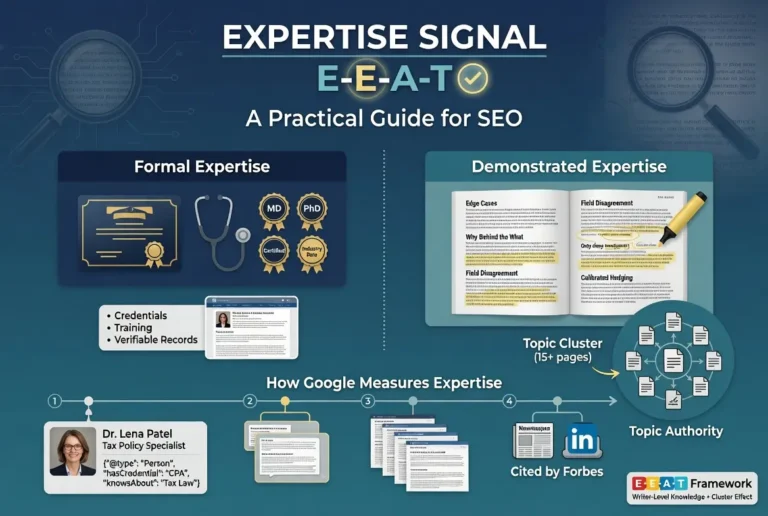
Expertise is the second letter and the one most commonly misunderstood as being purely about formal credentials. Google’s framework recognizes both formal Expertise and demonstrated Expertise, and the framework treats them differently depending on the topic and the writing context.
Formal Expertise is the credentials version. Medical degrees, professional certifications, academic appointments, recognized industry positions. The signal is verifiable through external records and is the easiest to evaluate because the credential either exists or it does not. The framework values formal Expertise, particularly for topics where formal training is the recognized path to competence.
Demonstrated Expertise is the writing-itself version. The content shows knowledge through how it handles edge cases, how it explains the why behind the what, how it engages with disagreement in the field, and how it surfaces details that only someone with deep working knowledge would surface. The signal is observable in the content directly and does not require external verification. The framework values demonstrated Expertise even when formal credentials are absent, particularly for topics where the recognized path to competence is not credentialing-based.
The two forms are not interchangeable, but they reinforce each other. A writer with formal credentials who cannot demonstrate the knowledge in their writing has a weaker Expertise profile than the credentials suggest. A writer with no formal credentials who demonstrates the knowledge consistently across substantive content has a real Expertise profile despite the absence of a credential. The strongest configurations have both, and the framework treats them as parallel inputs into the broader Expertise judgment.
The author bio is where formal Expertise gets surfaced operationally, and the Schema.org Person markup is where the bio information becomes machine-readable. Sites that publish substantive content under named bylines with verifiable credential links produce a stronger Expertise signal than sites that publish under generic admin accounts or hide the authorship layer entirely. The visibility of authorship is part of the signal.
The honest read on Expertise in 2026 is that the bar has moved. The web has filled with AI-generated content that mimics the surface features of expertise without the underlying knowledge. The framework’s response has been to weight demonstrated Expertise more heavily relative to surface features. Pages that recite information in patterns that match generic AI output without the texture of real working knowledge are increasingly identified as such, and the credential layer alone does not save them.
For the deeper treatment of how Expertise is demonstrated through writing, how Topic Authority builds at the cluster level, and the operational patterns for surfacing both formal and demonstrated Expertise on a site, the tier article on Expertise covers the full operational guide.
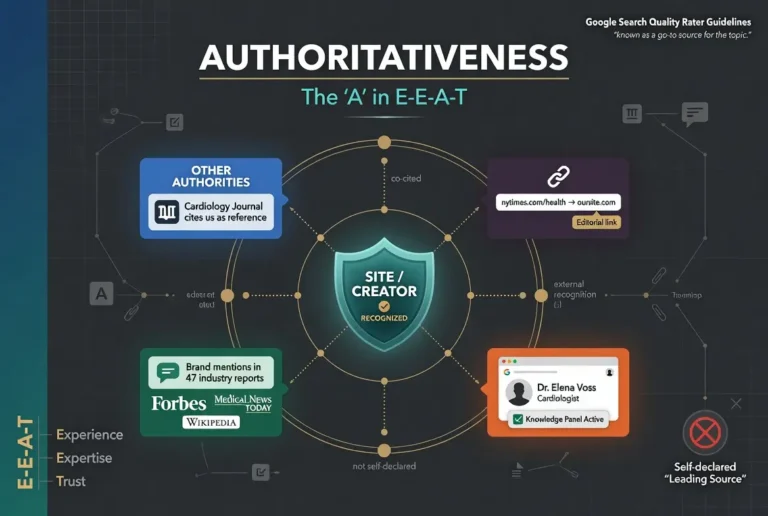
Authoritativeness: The Entity Layer
Authoritativeness is the third letter and the one that shifts the locus of evaluation from the page itself to the broader web around the page. Where Experience and Expertise live at the writer level, Authoritativeness lives at the recognition level. The question changes from whether the writer knows the topic to whether the rest of the field treats this writer or this site as a recognized source.
The shift matters because Authoritativeness cannot be self-generated in the way the first two letters can. A writer can develop Experience through their own work and Expertise through their own training. Authoritativeness is conferred by other recognized voices in the field pointing to the writer or the site as a reference. The signal is externally produced, and a site has zero Authoritativeness on day one of publishing regardless of how strong its other signals are.
The proxy signals Google’s systems use to estimate Authoritativeness break into four categories. Link-based signals from authoritative sites in the relevant topical neighborhood. Brand-based signals including unlinked mentions in journalism and industry coverage. Content-based signals at the topical level showing depth and consistent coverage of a subject area. Entity-based signals from the knowledge graph, including Wikipedia presence, knowledge panel recognition, and entity disambiguation through schema markup. All four reinforce each other, and Authoritativeness built on only one category is fragile.
The topic-specific nature of Authoritativeness is one of the most operationally important details in the framework. A site can be highly authoritative on home improvement and have zero authority on medical topics, and Google treats those as separate evaluations. The implication is that Authoritativeness builds at the topic level, not at the site level in aggregate. The strategic choice of which topics to pursue is fundamental to how the signal develops, and operators who try to build Authoritativeness across too broad a topical surface usually end up with no Authoritativeness anywhere.
The most common Authoritativeness mistake is the manufactured recognition trap. Operators invest heavily in tactics that produce the surface features of Authoritativeness without producing the underlying recognition those features are supposed to signal. Coordinated guest posting campaigns. Paid press release syndication. Self-placed bylines across thin sites. The pattern produces a profile that looks authoritative in third-party tools but increasingly fails to translate to actual ranking benefit as Google’s systems improve at distinguishing engineered patterns from organic recognition.
The honest path to Authoritativeness is the slower one. Build the substantive content base first. Participate in the topic conversation where it already happens. Create the surface area that makes the site a natural reference for journalists and other authoritative voices. Let the compounding phase emerge as a function of the preceding work. The path takes years rather than months, and the operators who succeed at it are the ones who understood from the beginning that the work could not be shortcut.
For the deeper treatment of Topic Authority, backlink quality at the Authoritativeness level, brand mentions and unlinked citations, knowledge panel recognition, and the four-stage progression for building Authoritativeness from zero, the tier article on Authoritativeness covers the full operational guide.
Trust: The Foundation Google Cares Most About
Trust is the fourth letter and the one Google has explicitly named the most important of the four. The framework diagram puts Trust at the center rather than treating it as one quadrant among four, and the official guidance is direct about the hierarchy. Experience, Expertise, and Authoritativeness all feed into Trust. A site that fails on Trust fails the framework regardless of how strong the other three signals are.
The reasoning behind this elevation is straightforward. Google’s product is the search results page. The product fails when users land on pages that mislead them, harm them, or do not reliably deliver what the page promises. The other three letters are useful diagnostic signals, but the question Google’s systems are ultimately optimizing for is whether the page is reliable. Trust is the dimension that names that question explicitly.
The proxy signals Google’s systems use to estimate Trust break into four categories. Accuracy signals, including whether factual claims align with authoritative coverage and whether citations actually support the claims being made. Transparency signals, including whether the site identifies who runs it and explains how content is produced. Technical trust signals, including HTTPS, security headers, and stable hosting infrastructure. Reputation signals, including how the broader web treats the site and whether journalists, researchers, and other authoritative voices have written about it in ways that confirm its legitimacy.
The hierarchy has a practical implication that operators frequently miss. A page can demonstrate full Experience through first-person testing photographs, full Expertise through verified credentials, and full Authoritativeness through editorial citations from recognized voices, and still fail the framework if the page is making inaccurate claims, hiding ownership, lacking basic security, or operating as part of a deceptive site structure. The other three signals do not save the page. Trust is the gate.
The reverse is also worth naming. A page can have modest Experience, average Expertise, and limited Authoritativeness and still pass the framework if the Trust signals are strong. Honesty about what the page is, accuracy in what it claims, transparency about the site’s operations, and reasonable security infrastructure can carry a page that lacks the other dimensions. The compounding effect runs through Trust.
The framework adjusts Trust scrutiny based on the topic. YMYL content carries elevated Trust requirements that the baseline does not satisfy, and the next section covers that adjustment in more detail. The general pattern is that the cost of being wrong determines how much Trust the framework requires before the page is treated as reliable. Higher cost means higher requirement.
For the deeper treatment of accuracy as the substrate of Trust, transparency signals through About and Contact pages and editorial policies, technical trust infrastructure, YMYL adjustments, and the four-stage progression for building Trust from zero, the tier article on Trust covers the full operational guide.
Why E-E-A-T Matters More for YMYL Content
The framework adjusts based on topic, and the most important adjustment happens for content classified as YMYL. The acronym stands for Your Money or Your Life, and it covers topics where inaccurate or misleading content can cause real harm to readers. Health, finance, legal, safety, civics, and major life decisions all fall under the YMYL umbrella, and Trust scrutiny is highest there.
The adjustment is not subtle. E-E-A-T signals that would pass the framework on a recipe site fail the framework on a medical site. The reasoning is proportional. The cost of an inaccurate recipe is a bad meal. The cost of inaccurate medical advice is potentially someone’s health. The framework treats these as different evaluations because the consequences of getting it wrong are different.
The operational implications break across all four letters. Experience requirements tighten because the expected first-hand contact with a YMYL topic is more substantive than for general topics. Expertise requirements tighten because the recognized path to competence on YMYL topics typically involves formal credentialing that the framework expects to see surfaced. Authoritativeness requirements tighten because the recognized voices on YMYL topics are typically institutions with a long track record rather than newer entrants. Trust requirements tighten because the baseline transparency, accuracy, and security stack that passes the framework on general topics fails on YMYL topics.
The category of who counts as an authoritative source on YMYL topics also tightens. A site covering general home improvement can pass the framework with practical writers and demonstrated experience. A site covering medical topics needs medical professionals reviewing the content and making the medical claims, not lay writers researching from secondary sources. The framework does not treat these as equivalent regardless of how well the lay writer researches.
One detail that matters operationally. YMYL classification is not a binary at the site level. Individual pages within a broader site can carry YMYL implications even when the site as a whole is not primarily YMYL. A general lifestyle site that publishes a single article on prescription medication is being evaluated under YMYL standards for that page even though the rest of the site is not. The page-level evaluation is what matters for that specific page.
The implication for operators considering YMYL content is that the investment to pass the framework on YMYL topics is substantially higher than for general topics, and the path is harder for newer sites. Sites with limited Trust infrastructure can rank for general topics through quality content alone. Sites with limited Trust infrastructure cannot rank for YMYL topics through content alone. The infrastructure has to come first.
How Google Actually Measures E-E-A-T
The most consequential point about how E-E-A-T affects rankings is also the one operators most often get wrong. E-E-A-T is not a direct ranking factor. The framework lives in the Quality Rater Guidelines and is used by human evaluators whose feedback trains Google’s ranking systems over time. Google’s algorithms cannot directly measure E-E-A-T the way a human rater can. They measure proxies for it.
The distinction matters because operators frequently optimize for E-E-A-T as if it were a checklist of features that Google’s algorithms read directly. The actual mechanism is one step removed. Quality raters evaluate pages against the framework. Google’s systems train on the rater feedback and develop algorithmic proxies that approximate the rater judgments at scale. The proxies improve over time as the systems get better at identifying the patterns the raters consistently flag.
The proxies break across the four letters. Experience proxies include first-person photographs, anecdotal markers, and hedging patterns that match real first-hand contact. Expertise proxies include named bylines, credential schema markup, and writing patterns that demonstrate working knowledge. Authoritativeness proxies include link-based signals, brand mention patterns, knowledge graph entity recognition, and topical depth at the site level. Trust proxies include accuracy alignment with authoritative coverage, transparency surface features, technical security signals, and reputation signals from the broader web.
The proxies are imperfect, and Google has been transparent about this. The systems sometimes flag pages that pass the framework on rater evaluation, and the systems sometimes pass pages that would fail rater evaluation. The proxies improve over time, but the improvement is gradual, and operators who optimize purely for the proxies without optimizing for the underlying signals end up with profiles that look strong in third-party tools but fail when the proxies catch up.
The implication is that the work that scales is the work that produces the underlying signals rather than just the surface features the proxies measure. Real first-hand experience produces Experience signals that the proxies will increasingly recognize. Real demonstrated knowledge produces Expertise signals that hold up over time. Real recognition from authoritative voices produces Authoritativeness signals that compound. Real transparency, accuracy, and security produce Trust signals that the proxies converge on. The operators who succeed at E-E-A-T over multi-year time horizons are the ones who built the underlying quality and let the proxies catch up rather than gaming the proxies and hoping the underlying quality was not needed.
One worth flagging directly. The helpful content guidance Google has published reinforces this orientation. Content created primarily for search engines rather than people increasingly fails the framework as the proxies improve at distinguishing the two. Content created primarily for people that happens to also rank is the configuration that scales. The relationship between AI content production and E-E-A-T is where this tension is most visible in 2026. The framing is the inverse of how SEO was practiced for most of its history, and it is the framing that maps onto how E-E-A-T actually operates in 2026.
The Practical E-E-A-T Audit
The framework is most useful when operators turn it into a practical audit they can run against a site to identify which letters need investment. The audit breaks across the four signals and produces a list of gaps that the strategic work can then address.
For Experience, the audit asks whether published content reflects first-hand contact with the topics covered. Photographs of actual products being tested rather than stock images. Anecdotes that include details only someone present would include. Hedging patterns that match the writer’s actual confidence rather than the position the writing implies. Sites that publish credentialed content with no Experience markers have a gap in the first letter that the audit surfaces immediately.
For Expertise, the audit asks whether the writing demonstrates the knowledge it claims. Engagement with edge cases. Explanation of the why behind the what. Visible engagement with disagreement in the field. Substantive depth on subjects rather than surface coverage that recites consensus without engagement. Author bios that surface formal credentials where they exist and demonstrated competence where formal credentials do not. The audit identifies sites where the writing position implies expertise the content does not actually demonstrate.
For Authoritativeness, the audit asks whether the broader web treats the site as a recognized source on its topics. Backlinks from authoritative sites in the relevant topical neighborhood. Brand mentions in journalism and industry coverage. Knowledge graph entity recognition where applicable. Topical depth that signals seriousness about the subject area rather than scattered coverage. The audit identifies sites where investment in content has not been matched by investment in the recognition layer.
For Trust, the audit covers the most operational ground because Trust has the most surface features. HTTPS and the broader technical security stack. About page that names who runs the site and what their qualifications are. Working contact methods. Editorial policy that explains how content is produced and updated. Author bylines on every page where authorship matters. Schema markup that makes the transparency information machine-readable. Privacy policy and applicable regulatory compliance. Accuracy discipline in the published content. The audit identifies sites where any of these baseline elements is missing or weak.
The audit produces a list of gaps. The strategic work is the prioritization. Trust gaps are usually the highest priority because Trust is the most weighted factor and most Trust gaps are addressable in the short term. Authoritativeness gaps are usually the slowest to close because Authoritativeness is conferred externally and accumulates over time. Experience and Expertise gaps fall in between, addressable through changes in how content is produced and surfaced.
For sites that want a structured starting point on the technical and credibility audit layers specifically, the Credibility discipline covers the operational architecture, and the Content discipline covers the production standard.
Verdict
E-E-A-T is the operating definition of content quality that Google’s systems have been converging on for over a decade. The framework names four signals: Experience, Expertise, Authoritativeness, and Trust, and the four work as a system rather than as independent checklists. Trust is the foundation Google cares about most, and the other three letters function as inputs that feed into the Trust judgment.
The framework is not a direct ranking factor in the algorithmic sense. It lives in the Quality Rater Guidelines and shapes the rater evaluations that train Google’s ranking systems over time. The systems develop algorithmic proxies for each signal, the proxies improve as the systems mature, and the operators who succeed at E-E-A-T over multi-year time horizons are the ones who build the underlying quality and let the proxies catch up rather than gaming the proxies in isolation.
For YMYL topics, the scrutiny is elevated across all four letters, and the baseline that passes the framework on general topics fails on health, finance, legal, safety, and civic content. The infrastructure investment for YMYL is higher, and the path for newer sites is harder.
The practical sequence for operators is the audit. Identify which letters have gaps. Prioritize Trust because it is the most weighted factor and most Trust gaps are short-term addressable. Plan the longer Authoritativeness work as a multi-year accumulation that cannot be shortcut. Build Experience and Expertise into the content production process from the first article forward.
The same E-E-A-T signals that drive organic rankings now determine whether AI platforms like ChatGPT and Google AI Overviews cite your brand in AI-generated responses, making the framework even more consequential than when it only influenced traditional search.
The deeper treatment of each letter lives in the four sibling articles. The article on Experience covers the first letter and the new E added in 2022. The article on Expertise covers the second letter and the distinction between formal and demonstrated knowledge. The article on Authoritativeness covers the third letter and the external recognition layer. The article on Trust covers the fourth letter and the foundation Google has named the most important factor in the framework.
Frequently Asked Questions
What does E-E-A-T stand for?
E-E-A-T stands for Experience, Expertise, Authoritativeness, and Trust. It is the quality framework from Google’s Search Quality Rater Guidelines that describes the qualities Google’s algorithms are trying to surface in search results. The framework started as E-A-T in 2014 and added Experience as the fourth letter in December 2022.
Is E-E-A-T a direct ranking factor?
No. E-E-A-T is a quality framework used by human raters, not a direct ranking factor. The rater feedback trains Google’s ranking systems over time, and the systems develop algorithmic proxies for each signal. The proxies influence rankings through other mechanisms, but E-E-A-T itself is not measured directly by the algorithms.
Which letter of E-E-A-T is most important?
Trust. Google has stated this directly, and the framework diagram in the Quality Rater Guidelines puts Trust at the center with Experience, Expertise, and Authoritativeness functioning as inputs. A page that fails on Trust fails the framework regardless of how strong it scores on the other three signals.
What is the difference between Experience and Expertise?
Experience is built through first-hand contact with a topic. Expertise is built through training, credentials, and demonstrated knowledge. The two are related but not interchangeable. A writer can have full Expertise without Experience, and a writer can have full Experience without formal Expertise. The framework treats them as separate signals because they come from different sources.
What is YMYL content and how does E-E-A-T apply?
YMYL stands for Your Money or Your Life and covers topics where inaccurate content can harm readers, including health, finance, legal, safety, and major life decisions. E-E-A-T scrutiny is elevated for YMYL content across all four letters, and the baseline that passes the framework on general topics fails on YMYL topics.
How long does it take to build E-E-A-T from zero?
The Trust baseline can be locked in the first month through technical infrastructure and the transparency stack. Experience and Expertise build into the content production process from the first published article. Authoritativeness accumulates over years as the substantive work earns external recognition. The full profile is a multi-year accumulation rather than a short-term project.
Can a site rank without strong E-E-A-T?
For low-competition non-YMYL topics, sites can rank without strong E-E-A-T signals because the framework’s weight in the algorithmic proxies is lower for those topics. For competitive topics and YMYL topics, ranking without strong E-E-A-T becomes increasingly difficult as the proxies improve at distinguishing pages that meet the framework from pages that do not.
Where can I read Google’s official E-E-A-T documentation?
The full framework lives in Google’s Search Quality Rater Guidelines, which is publicly available as a PDF on Google’s developer site. Google’s Search Central blog also publishes updates and explanatory posts whenever the framework is revised, including the December 2022 announcement when Experience was added as the fourth letter.