AI Summary
What is this article about? This article explains how Google’s helpful content framework evaluates AI generated content. The framework does not distinguish between AI and human production. It evaluates whether content was created primarily for people or primarily for search engines. That evaluation determines ranking outcomes regardless of who or what produced the writing.
What it is and who it is for: This article is for site owners, content producers, and SEO practitioners who need to understand how Google’s quality evaluation systems interact with AI generated content. It covers what the framework actually measures, how the evaluation works at the page and site level, and why the AI versus human framing misses the variable that predicts ranking outcomes.
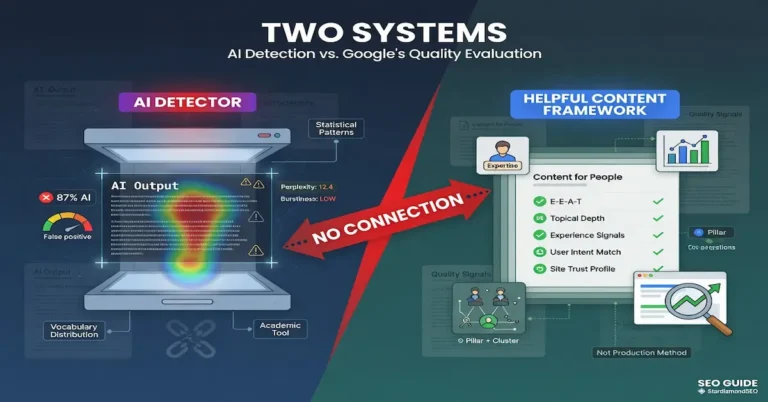
The rule: The helpful content framework evaluates orientation, not production method. Content oriented toward helping people ranks. Content oriented toward capturing search impressions does not. The framework applies this evaluation identically to AI content and human content because the production method is not the dimension being measured.
A Framework, Not a Filter
The helpful content framework is not an AI content filter. It is not a detection system. It is not a penalty mechanism designed to identify and suppress machine-generated text. It is a quality evaluation framework that Google’s ranking systems use to determine whether content deserves to be surfaced in search results. The framework was introduced in August 2022, months before ChatGPT launched and years before AI content became the dominant concern in SEO discussions.
The framework evaluates content against a set of quality signals that apply to all content regardless of production method. Does the content provide original information or analysis? Does it demonstrate genuine expertise on the topic? Does it serve the searcher’s intent? Does the site show editorial standards and transparency? These questions are production-method-agnostic. A human writer can fail every one of them. An AI-assisted production process can pass every one of them. The variable is the quality of the output, not the identity of the producer.
Understanding the framework as a quality evaluation rather than an AI filter changes how operators approach AI content production. The question shifts from “will Google detect that this is AI” to “does this content meet the quality standard the framework describes.” The first question leads to detection evasion, humanizer tools, and wasted effort on the wrong problem. The second question leads to editorial discipline, quality investment, and content that ranks because it deserves to.
The Four Evaluation Categories
The helpful content framework evaluates content across four categories. Each category asks specific questions that Google’s ranking systems approximate through algorithmic signals. Understanding the categories clarifies what AI content needs to demonstrate to pass the evaluation.
Audience Value
Does the content provide value that the searcher cannot easily find elsewhere? The framework rewards content that offers original information, unique analysis, or a perspective the existing results do not provide. Content that restates what already ranks without adding to it fails this category because it provides no incremental value to the searcher.
AI drafts fail this category by default because they synthesize from existing content. The synthesis is competent but not original. The editorial layer is where audience value enters: the operator’s original data, their specific testing results, their recommendations based on experience the AI does not have. Without the editorial layer, the AI output is a restatement. With it, the output adds something the existing results lack.
Expertise Demonstration
Does the content demonstrate that the creator has genuine knowledge of the topic? The framework looks for engagement with edge cases, explanation of the reasoning behind recommendations, depth that goes past surface-level coverage, and the specific details that only someone with working knowledge would include.
This is where the E-E-A-T framework and the helpful content framework converge. Experience and Expertise signals are how the content demonstrates that the creator knows the topic from direct involvement rather than from research synthesis. AI content that lacks these signals reads as competent summarization. AI content that includes them reads as authoritative coverage. The signals are added by the operator during the editorial process, not generated by the AI during the drafting process.
User Satisfaction
Does the content match the search intent and deliver what the page title promises? The framework evaluates whether users who arrive from search are satisfied by what they find or whether they return to the search results looking for a better answer. The behavioral signals that approximate satisfaction, time on page relative to content length, scroll depth, return-to-SERP rate, are not specific to AI content. They measure whether the content served the purpose the searcher had when they clicked.
AI content fails user satisfaction when it covers a topic broadly but does not answer the specific question the searcher asked. A 2,000-word article about “content pillars” that defines the concept and lists benefits without explaining how to actually build one satisfies a definition query but not a how-to query. The failure is intent mismatch, not AI detection. The same failure occurs with human content that covers the wrong angle for the keyword’s dominant intent.
Site-Level Trust
Does the site demonstrate editorial standards, transparency, and reliability across its publishing? The framework evaluates trust at the site level, not just the page level. A site that publishes ten AI-generated articles with strong editorial layers builds positive site-level signals. A site that publishes 500 AI-generated articles with no editorial layer builds negative site-level signals that suppress even the individual pages that might pass on their own.
The site-level evaluation is why the volume play fails. Mass-producing AI content across a broad topical surface without editorial investment produces a site-level pattern that the framework identifies as content-for-search-engines rather than content-for-people. The pattern is detectable not because AI involvement is detectable but because the aggregate quality profile of mass-produced content is statistically distinct from the aggregate quality profile of editorially managed content.
The Site-Level Signal
One of the most consequential aspects of the helpful content framework is that it operates at the site level in addition to the page level. The framework generates a site-wide signal based on the aggregate quality of all published content. A site with predominantly helpful content develops a positive signal that benefits even weaker individual pages. A site with predominantly unhelpful content develops a negative signal that suppresses even stronger individual pages.
This is the mechanism that makes the AI content volume play fail over time. A site that publishes 100 AI-generated articles per month without editorial investment accumulates unhelpful content faster than any individual article can be improved. The site-level signal degrades with each publication. The degradation eventually pulls down the pages that might have performed well individually because they are evaluated in the context of a site that the framework has classified as producing primarily unhelpful content.
The recovery from a negative site-level signal requires removing or substantially improving the unhelpful content until the ratio of helpful to unhelpful content shifts. Google has confirmed that the signal updates over time as the content profile changes. The update is not instant. Sites that accumulated months of unhelpful content may wait months for the signal to recover after improvements are made. The delay is part of why the volume play is so destructive: the damage accumulates faster than the recovery progresses.
For operators using AI in their production process, the site-level signal means that every article matters. Publishing one strong article and five weak ones does not produce a net positive. The five weak ones degrade the signal that the one strong one benefits from. Scaling AI content production responsibly means maintaining editorial quality across every publication, not just the ones targeting the highest-value keywords.
The Four Content Configurations
The actual variables that predict ranking outcomes produce four configurations, not two. The AI-versus-human binary collapses these into a misleading simplification.
Human content, people-first orientation. Content produced by human writers who understand the topic, serve the reader’s needs, and produce genuine value. This configuration has always ranked and continues to rank. It is the baseline the framework was designed to identify and reward.
Human content, search-first orientation. Content produced by human writers working from keyword lists, targeting search volume, and producing articles designed to rank rather than to help. Thin affiliate content, keyword-stuffed listicles, and rewritten aggregation. This configuration fails the framework regardless of human authorship because the orientation is wrong.
AI content, people-first orientation. Content produced with AI assistance where the operator brings genuine expertise, applies a substantive editorial layer, and produces output that serves the reader with original value. This configuration ranks comparably to the first because the orientation is correct and the production method is irrelevant to the evaluation.
AI content, search-first orientation. Content mass-produced with AI to capture search impressions across broad topical surfaces without editorial investment. The volume play. This configuration fails the framework because the orientation is wrong, and it fails more visibly than the human equivalent because AI makes volume cheap enough that the pattern accumulates faster.
The framework evaluates orientation. Configurations one and three pass. Configurations two and four fail. The production method is a variable that correlates with orientation in the data but is not the variable the framework measures. Operators who understand this produce AI content in configuration three. Operators who think the variable is production method waste effort on detection evasion while their content fails for reasons they are not addressing.
What the Ranking Data Shows
The empirical data on AI content performance confirms the framework’s logic when parsed correctly.
AI content underperforms on average. This is true in every large-scale study. The average AI-generated article ranks lower and accumulates less traffic than the average human-written article. The finding is real and frequently cited as evidence that Google penalizes AI content.
The underperformance concentrates at the volume end. When the data is segmented by production volume, the AI content published at scale (50+ articles per month per site with minimal editorial investment) accounts for the majority of the aggregate underperformance. This segment drags the average down dramatically because the volume is high and the quality is low.
AI content with editorial discipline performs comparably. When studies control for editorial investment, meaning they compare AI content that received substantive editorial work against human content produced with the same level of care, the performance gap closes or disappears. The controlled comparison isolates the variable that matters: editorial quality, not production method.
Human content without editorial discipline also underperforms. Thin affiliate content, keyword-stuffed articles, and rewritten aggregation produced by human writers performs comparably to AI content produced with the same orientation. The underperformance is not a consequence of the producer’s identity. It is a consequence of the orientation.
The data and the framework agree. The framework says orientation matters and production method does not. The data shows that orientation predicts performance and production method does not, once orientation is controlled for. The alignment between the stated framework and the observable data is complete.
Practical Implications for AI Content Producers
If you use AI in your content production process, the helpful content framework requires three things from you.
First, every publication must pass the quality evaluation on its own merits. The framework does not grade on a curve. Each article is evaluated against the criteria, and articles that fail contribute to the negative site-level signal. Publishing five articles per week with AI is not an advantage if three of those articles fail the evaluation. The three failures degrade the signal that the two successes benefit from. Publish fewer, better articles rather than more, weaker ones.
Second, the editorial layer is not optional. AI drafts without editorial investment produce content in configuration four, the volume play that fails the framework. The editorial layer, adding original insight, experience signals, accuracy verification, and genuine depth, is what moves AI content from configuration four to configuration three. The layer costs time. The time is the investment. Without it, the AI output is a liability, not an asset.
Third, monitor the site-level signal through Search Console. If indexed pages are being excluded from search results with “Crawled, currently not indexed” status, and the exclusions are concentrated on recent AI-produced content, the site-level signal may be degrading. The appropriate response is to improve or remove the content that is failing, not to publish more content hoping to outrun the signal. The signal does not work that way. More unhelpful content makes it worse, not better.
The workflow for producing AI content that ranks is documented in detail in the AI Content Creation cluster. The framework is clear. The process that follows from it is specific. The operators who follow it produce results. The operators who ignore it produce content that fails for reasons they misattribute to AI detection.
FAQ
Does Google’s helpful content update target AI content specifically?
No. The helpful content framework targets content created primarily for search engines rather than for people. The framework was introduced in August 2022 before ChatGPT launched and applies to all content regardless of production method. AI content fails the framework more often than human content on average because AI makes the volume play cheap, not because the framework targets AI specifically.
Can AI generated content rank on Google in 2026?
Yes. AI generated content that passes the helpful content framework ranks comparably to human content that passes the same framework. The content must demonstrate original value, genuine expertise, and reader-first orientation. AI content that meets these criteria through a substantive editorial process ranks and holds. AI content that lacks editorial investment fails the framework and underperforms.
What is the site-level helpful content signal?
The helpful content framework generates a site-wide quality signal based on the aggregate quality of all published content. A site with predominantly helpful content develops a positive signal that benefits all pages. A site with predominantly unhelpful content develops a negative signal that suppresses all pages, including individually strong ones. The signal updates over time as the content profile changes.
How does the helpful content framework evaluate expertise?
The framework evaluates whether the content demonstrates genuine knowledge through engagement with edge cases, explanation of reasoning behind recommendations, depth beyond surface coverage, and specific details that only someone with working knowledge would include. These signals align with the Experience and Expertise components of Google’s E-E-A-T framework. AI drafts without editorial investment typically lack these signals because AI synthesizes from existing content rather than generating insight from direct experience.
What is the difference between content for people and content for search engines?
Content for people answers the searcher’s question with genuine value, original insight, and useful information the reader can act on. Content for search engines targets keyword volume, follows structural templates designed to rank rather than inform, and produces coverage that exists to capture impressions rather than to help the person who clicks. The helpful content framework evaluates this orientation and rewards the first while suppressing the second.
How long does it take to recover from a negative helpful content signal?
Recovery requires removing or substantially improving the unhelpful content until the ratio of helpful to unhelpful content shifts. Google has confirmed the signal updates over time but has not specified a fixed timeline. Sites that accumulated months of unhelpful content typically wait months for recovery after improvements are made. The recovery is not instant because the signal is based on sustained content quality patterns rather than individual page changes.