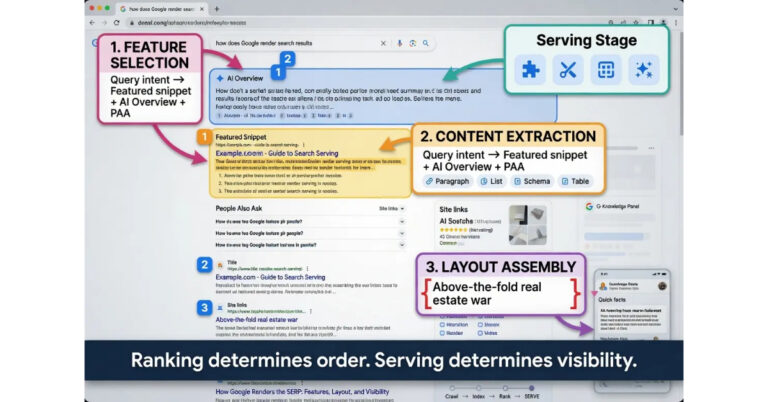
How Google Crawls the Web: Discovery, Retrieval, and Crawl Budget
AI Summary
What is the crawling stage? The crawling stage is where Googlebot discovers URLs and fetches their content. The stage has two distinct functions: discovery (finding URLs to crawl) and retrieval (fetching the content of URLs that have been found). Both functions matter for SEO, and operators who treat crawling as one undifferentiated activity miss the leverage points that exist at each function.
What it is and who it is for: The crawl stage matters for any operator who needs to diagnose why pages are not appearing in Google, understand why some content gets indexed faster than others, or design site architecture that produces sustainable crawl coverage. Crawling is the first stage of the four-stage Google Search pipeline, and pages that fail at the crawl stage cannot reach any later stage regardless of their content quality.
The rule: Discovery and retrieval are separate functions with separate failure modes. Operators who match interventions to functions produce sustainable crawl coverage. Operators who treat crawling as one activity often fix the wrong function and produce no improvement.
Table of Contents
The Three Discovery Pathways
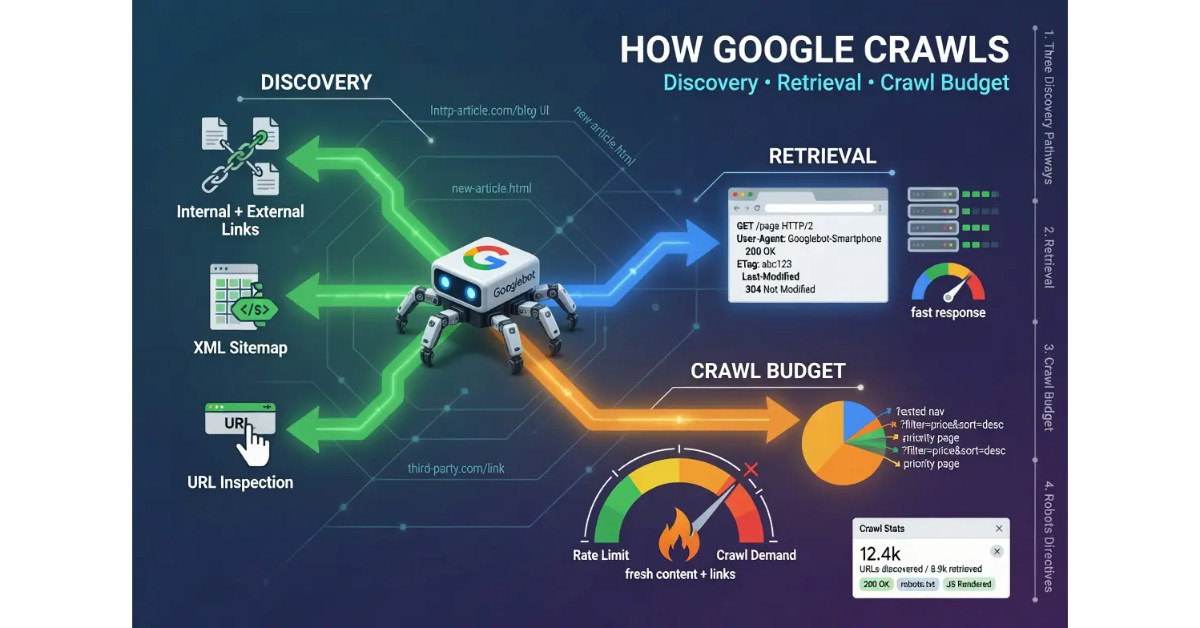
Discovery is how Googlebot finds URLs to crawl. The function operates on a simple input-output model: Google’s systems need a list of URLs to fetch, and the discovery function produces that list through three primary pathways. Operators who understand the pathways can design their sites to produce sustained discovery without manual intervention for every page. Operators who do not understand them often have content that never gets crawled because Google has no mechanism to find it.
The first pathway is internal and external linking. Googlebot follows links from pages it already knows about to find new URLs. When Googlebot crawls a page that links to a previously unknown URL, that URL gets added to the queue of pages to crawl. The pathway is the most reliable mechanism for sustained discovery on an established site because it does not require any operator action beyond publishing content with internal links. New articles published on a site with strong internal linking get discovered automatically as Googlebot recrawls the linking pages.
External linking works the same way but operates across domain boundaries. When a third-party site links to a URL, Googlebot discovers that URL during its crawl of the third-party site. The mechanism is what allows new domains and orphaned pages to be discovered before the operator submits anything manually. External link discovery is also what makes brand mentions and editorial citations valuable for crawl signal independent of their ranking equity contribution.
The second pathway is sitemap submission. Operators who submit XML sitemaps through Google Search Console give Googlebot a direct list of URLs to consider for crawling. The sitemap is treated as a hint rather than an instruction. Google evaluates which sitemap URLs to crawl based on its broader crawl prioritization, and not every URL in a sitemap will be crawled even if the file is valid. Sitemaps work best for new content that does not yet have inbound links, where the alternative is waiting for Googlebot to discover the URL through some other pathway.
Sitemap maintenance matters more than most operators initially expect. Outdated sitemaps containing dead URLs, redirected URLs, or URLs blocked by robots.txt produce signal noise that Google treats as a quality issue with the sitemap itself. Sitemaps that consistently surface valid, crawlable URLs at appropriate priorities are weighted differently than sitemaps that contain errors. Operators who submit sitemaps and never update them produce diminishing crawl benefit over time as the sitemap drifts from the actual site state.
The third pathway is direct submission through the URL Inspection tool in Google Search Console. The tool lets operators submit specific URLs for immediate crawling. Direct submission works for individual URLs and is useful for surfacing newly published critical content, getting recently fixed pages re-evaluated, or testing whether a URL is even reachable by Googlebot. The pathway does not scale; operators cannot submit hundreds of URLs efficiently this way. Direct submission is a precision tool, not a bulk discovery mechanism.
The honest read on discovery is that linking remains the dominant pathway for sustained crawl coverage on established sites. Sitemaps work as a supplement and a hint mechanism. Direct submission works for individual high-priority URLs. Operations that rely solely on sitemaps without internal linking infrastructure produce slower discovery than operations that combine all three pathways. Operations that rely solely on internal linking without sitemaps lose the supplementary signal that sitemaps provide for new content. The integrated approach is what produces consistent discovery at scale.
For more on how the discovery output flows into the next stage of the pipeline, the pillar guide on How Google Search Works covers the full four-stage system. The sibling articles on How Google Indexes Pages, How Google Ranks Search Results, and How Google Renders the SERP cover the other stages.
How Retrieval Actually Works
Retrieval is the actual fetch operation. Once Googlebot has a URL to crawl, it makes an HTTP request to the URL, receives a response from the server, and processes whatever the server returns. The retrieval function depends on factors the discovery function does not touch: server availability, response codes, content delivery speed, and the presence or absence of directives that tell Googlebot how to handle the URL. A site can have perfect discovery but broken retrieval, which produces pages that Googlebot tries to fetch but cannot successfully process.
The HTTP request that Googlebot makes is a standard browser-like request, but with specific identification in the user agent string. The two most relevant Googlebot user agents are Googlebot Smartphone (the primary crawler for most sites since the mobile-first indexing transition) and Googlebot Desktop (used for specific desktop-only experiences and certain validation tasks). Operators can verify that traffic claiming to be Googlebot is actually Googlebot through reverse DNS lookups, which protect against fake Googlebot traffic from scrapers and bad actors.
The response the server returns determines what happens next. A 200 OK response with valid HTML content delivers the page content to Googlebot, which then passes it to the indexing pipeline. A 301 or 302 redirect tells Googlebot to follow the redirect to a different URL. A 404 or 410 response tells Googlebot the URL does not exist. A 5xx server error tells Googlebot the server is having problems, which causes Googlebot to retry the request later and reduce crawl frequency until the server stabilizes. Each response code triggers different downstream behavior, and operators who let server errors persist produce extended crawl impacts that take time to recover from.
Content delivery speed affects retrieval at scale. Googlebot allocates crawl resources to each site based partly on how quickly the server responds. Sites with fast server responses get more crawl requests in a given time window because each request consumes less crawler time. Sites with slow server responses get fewer crawl requests because the crawler has to wait longer for each one to complete. The relationship is not strictly linear, but it produces a measurable difference in crawl coverage between fast sites and slow sites of comparable authority.
Conditional requests are an underappreciated mechanism that affects retrieval efficiency. When Googlebot crawls a URL that has been crawled before, it can use the If-Modified-Since header or ETag values to ask whether the content has changed since the last crawl. Servers that respond with 304 Not Modified for unchanged content allow Googlebot to skip the full content download, which saves crawl budget for pages that have actually changed. Sites that do not implement conditional request handling force full re-downloads of every page on every crawl, which wastes crawl budget on content Google already has.
The retrieval function produces specific outputs that the indexing stage depends on. Each successful retrieval delivers the page content, the HTTP response headers, and any directives embedded in the response that affect how the indexing system should treat the page. Crawl directives include the X-Robots-Tag header, Last-Modified timestamps, ETag identifiers, and Content-Type specifications. Operators who use these headers correctly shape what happens at the indexing stage. Operators who use them incorrectly create indexing failures that look like crawl problems but actually originate at the directive layer.
The honest read on retrieval is that it is the function where most technical SEO work actually happens. Server health, response speed, header configuration, conditional request handling, and HTTPS implementation all live at the retrieval function. Operators who diagnose ranking problems often investigate content quality and link signals before checking whether the retrieval function is even working correctly, which produces wasted effort on the wrong layer. The retrieval check is the first diagnostic step, not the last.
Crawl Budget and What It Actually Means
Crawl budget is the concept that describes how much crawler attention Google allocates to a given site. The concept is real but commonly misunderstood. Crawl budget is not a fixed quota that operators can negotiate or purchase. The budget is an emergent property of how Google’s systems prioritize crawl resources across the entire web, and individual site allocation depends on factors the operator influences indirectly rather than directly.
The budget breaks across two component metrics that Google has discussed publicly: crawl rate limit and crawl demand. The crawl rate limit is the technical ceiling on how many requests Googlebot can make to a site without degrading the site’s performance for real users. Sites that can handle high request rates get higher rate limits. Sites that show signs of strain under crawler load get lower rate limits. The mechanism is protective; Google does not want its crawler to take a site down.
Crawl demand is the calculation of how much Google wants to crawl a given site. Demand is driven by factors including the popularity of the site’s URLs, the freshness of its content, the staleness of Google’s existing index data for the site, and the perceived value of recrawling existing pages versus crawling new ones. High-demand sites get crawled aggressively. Low-demand sites get crawled minimally. The actual crawl rate is the smaller of the rate limit and the demand, which means a site can have high rate limit headroom but low demand and still get crawled lightly.
The factors that increase crawl demand are the factors operators can actually influence. Publishing fresh content increases demand because Google wants to evaluate new pages. Earning external links increases demand because the link signal flags content as worth recrawling. Improving internal linking increases demand because internal signals tell Google which pages are important within the site. Reducing duplicate content increases demand because Google does not need to spend crawl budget on near-duplicate pages.
The factors that increase crawl rate limit are technical. Faster server response times let Googlebot make more requests in a given time window. Better caching and conditional request handling reduce the bandwidth cost per crawl request. Stable uptime prevents the rate limit from being throttled in response to server errors. Each of these factors raises the technical ceiling on crawl, even when crawl demand is the binding constraint.
Crawl budget primarily matters for large sites. Sites with hundreds of thousands of URLs face crawl coverage problems where Googlebot cannot reach every page on every crawl cycle. Operators of large sites need to think carefully about which URLs deserve crawl budget and which do not, often using robots.txt and noindex directives to deliberately exclude low-value URLs from crawl consideration. Sites with a few hundred or a few thousand pages rarely face crawl budget pressure because the budget exceeds the URL count by a wide margin.
The honest read on crawl budget is that for most sites, the budget concept is academic rather than operationally relevant. The site has fewer URLs than the available budget, so every page gets crawled regularly without budget management. The exception is large sites where coverage gaps appear, faceted navigation generates infinite URL combinations, or duplicate content patterns waste crawl resources. For those sites, crawl budget management is a meaningful operational discipline. For most other sites, the operational focus belongs on content quality and site architecture rather than crawl budget optimization.
Robots Directives and Crawl Control
Robots directives are the mechanisms operators use to tell Googlebot how to handle specific URLs. The directives operate at multiple layers, and operators who understand the layering can shape crawl behavior precisely. Operators who do not often produce conflicts between directives that result in unintended crawl outcomes.
The robots.txt file is the highest-level directive layer. The file sits at the root of a domain and tells crawlers which paths they can and cannot crawl. Disallow directives in robots.txt prevent Googlebot from crawling the specified paths entirely, which means the URLs are never fetched and never reach the indexing pipeline. The directive is preventive at the crawl layer, which is different from the noindex directive that operates at the indexing layer.
The distinction matters because robots.txt blocking and noindex have different downstream effects. A URL blocked by robots.txt cannot be crawled, which means Google cannot evaluate the URL’s content but may still index it based on external signals like inbound links. A URL allowed by robots.txt but marked noindex will be crawled, evaluated, and excluded from the index based on the operator’s directive. Operators who want to fully exclude content from Google’s index need to allow crawling and use noindex, not block crawling with robots.txt and assume that produces noindex behavior.
The robots meta tag is a page-level directive embedded in the HTML head. The most common values are noindex (do not index this page), nofollow (do not follow links from this page for crawl discovery), and noarchive (do not show a cached version in search results). Multiple values can be combined in a single tag. The directive only takes effect when Googlebot crawls the page and processes the meta tag, which means a page blocked by robots.txt cannot have its noindex directive read because the page is never crawled.
The X-Robots-Tag HTTP header provides the same directives as the robots meta tag but at the HTTP response layer. The header is useful for non-HTML files like PDFs and images where embedding a meta tag is not possible. The directive applies the same way as the meta tag once Googlebot processes the response.
The canonical link annotation is a directive at the indexing layer that tells Google which URL is the canonical version when multiple URLs contain similar content. The canonical does not affect whether a URL is crawled. It affects which URL gets indexed when the system identifies near-duplicates. Canonical management is its own discipline that interacts with crawl behavior because crawled pages with canonical pointers get processed differently than pages without them.
The hreflang annotation tells Google which language and regional versions of a page exist. The directive does not affect crawl directly but informs the serving stage decisions about which version to show to which users. Operators of multilingual or multi-regional sites need hreflang to prevent Google from confusing language variations as duplicate content.
The honest read on robots directives is that they are powerful but routinely misused. Operators sometimes block crawling with robots.txt thinking it prevents indexing, then discover the URLs in the index from external links Google saw. Operators sometimes apply noindex to pages they wanted excluded from search but not from crawl, then wonder why Googlebot still requests the URLs frequently. The directive layer is the layer where careful reading of the documentation pays off because the wrong directive produces the wrong outcome with the same surface-level intent.
JavaScript and the Rendering Layer
JavaScript rendering is the function that handles pages where the meaningful content is generated by client-side JavaScript rather than delivered in the initial HTML response. Googlebot’s handling of JavaScript-rendered content has evolved significantly over the past decade, and the current state is functional but introduces specific failure modes that operators need to understand.
The two-pass rendering model is how Google has historically handled JavaScript-heavy sites. The first pass crawls the initial HTML response and indexes whatever content is present in the raw HTML. The second pass renders the page through a headless Chromium-based renderer, executes the JavaScript, and indexes the post-render DOM. The two-pass model produces a delay between initial crawl and full content indexing because the rendering pass happens asynchronously after the initial crawl.
The rendering delay matters for pages that depend entirely on JavaScript for primary content. The initial HTML may contain only a skeleton with minimal content, and the actual page content appears only after JavaScript executes. During the gap between the initial crawl and the rendering pass, the page exists in Google’s index with only the skeleton content visible. Operators who launch JavaScript-heavy pages and expect immediate full indexing often see only partial content show up in the index for the first few days.
The rendering function has limitations that operators need to design around. Googlebot’s renderer is stateless, which means it does not preserve session data, cookies, or local storage across page loads. JavaScript that depends on session state will not work the same way for Googlebot as it does for a real user with an established session. JavaScript that requires user interaction to produce content will not produce that content for Googlebot because the renderer does not simulate user clicks or scrolls beyond what is needed to load above-the-fold content.
The lazy-loading pattern is one of the most common interactions between JavaScript rendering and crawl behavior. Pages that lazy-load images and content based on scroll position need specific implementation patterns to make the lazy-loaded content visible to Googlebot. The Intersection Observer API combined with native loading attributes produces lazy-loaded content that Googlebot can see. Custom lazy-loading implementations that depend on scroll events without proper signaling produce content that Googlebot cannot detect.
Server-side rendering and static site generation are the alternatives to client-side rendering that avoid the rendering delay entirely. Sites built with frameworks that produce server-rendered HTML deliver the full page content in the initial response, which means Googlebot can index the content on the first crawl without waiting for the rendering pass. The performance and indexing tradeoffs between rendering approaches are real, and operators choosing between them need to factor crawl behavior into the decision.
The honest read on JavaScript rendering is that Google handles it competently but the operational discipline matters. Sites that build for Googlebot’s rendering capabilities work well. Sites that ignore rendering and assume Googlebot sees what users see produce indexing problems that are hard to diagnose because the issue exists in the gap between initial crawl and full rendering. Operators who do not understand the rendering layer can spend weeks trying to fix problems that originate at this specific function.
Where Crawling Actually Fails
Crawl failures break across several recognizable patterns, and operators who can identify the specific failure mode can apply the targeted intervention that addresses it. Generic crawl optimization without diagnostic precision wastes effort on the wrong layer.
The first failure pattern is discovery starvation. New content gets published but Googlebot does not find the URLs to crawl. The pattern shows up as URLs that never appear in Google Search Console’s crawl reports, even after weeks of being live. The root causes include missing internal links to the new content, sitemaps that do not include the URLs, and orphan pages that exist on the server but are not linked from anywhere on the site. The fix is to add the discovery pathway that is missing, whether that is an internal link, a sitemap entry, or a direct submission.
The second failure pattern is retrieval errors. Googlebot finds the URL but cannot successfully fetch the content. The pattern shows up as crawl errors in Google Search Console, including server errors, timeout errors, and DNS resolution failures. The root causes include server downtime during crawl attempts, slow server response that exceeds Googlebot’s timeout threshold, and infrastructure problems that prevent the request from reaching the server at all. The fix is to address the underlying server health issue, which often requires hosting infrastructure improvements rather than SEO changes.
The third failure pattern is robots.txt blocking. Googlebot tries to crawl a URL but is blocked by a robots.txt directive that the operator did not intend. The pattern shows up as URLs that should be crawlable but show as blocked in Search Console. The root causes include overly broad disallow patterns, accidental blocking of important paths during site updates, and confusion between robots.txt and noindex semantics. The fix is to audit the robots.txt file and ensure the disallow patterns match the operator’s actual intent.
The fourth failure pattern is rendering breakdown. Googlebot crawls and retrieves the URL but cannot render the content correctly because the JavaScript breaks during the rendering pass. The pattern shows up in Search Console’s URL Inspection tool as rendered HTML that differs significantly from what users see. The root causes include JavaScript errors during rendering, dependencies on user state that Googlebot does not have, and content that loads only after user interactions. The fix is to test rendering through the URL Inspection tool’s live rendering feature and address the specific rendering issues that surface.
The fifth failure pattern is crawl budget waste. Googlebot is crawling URLs but spending its budget on low-value pages while high-value pages do not get crawled frequently enough. The pattern shows up on large sites as coverage gaps where important pages are crawled rarely while parameter URLs, faceted navigation combinations, and duplicate content variants consume crawl resources. The fix is to deliberately exclude low-value URL patterns from crawl through robots.txt or canonical management, which redirects budget toward the URLs that need it.
The sixth failure pattern is the canonical confusion. Googlebot crawls a URL but treats a different URL as canonical, which produces unexpected indexing behavior. The pattern shows up in Search Console as the “Duplicate, Google chose different canonical than user” status. The root causes include conflicting canonical signals between the URL itself, internal linking patterns, and HTTP headers. The fix is to align the canonical signals across all the layers so they consistently point at the operator’s preferred URL.
The honest read on crawl failures is that the failure mode determines the intervention. Operators who diagnose carefully can fix problems quickly. Operators who apply generic SEO interventions without diagnosing the failure mode often spend months making changes that cannot fix the actual issue because the issue lives at a different layer than the changes they are making.
Operator Leverage Points at the Crawl Stage
The leverage points for operators at the crawl stage break across the two functions of the stage: discovery and retrieval. Each function has interventions that act on it directly and other interventions that affect it indirectly through related stages.
Discovery leverage points include internal linking architecture, sitemap maintenance, and external link acquisition. Internal linking architecture produces sustained discovery without per-page intervention because Googlebot follows links naturally during regular crawls of the site. Sitemap maintenance ensures Google has the URL list it needs as a supplement to discovery through linking. External link acquisition produces cross-domain discovery that exposes new URLs to Googlebot through third-party sites it crawls.
The internal linking work that supports discovery is structural rather than tactical. Operators who design site architecture with clear hierarchy, topical clustering, and logical link patterns produce discovery infrastructure that scales with the site. Operators who rely on individual link insertions on a per-page basis produce fragile discovery that breaks when any single page changes.
Retrieval leverage points include server response optimization, conditional request handling, HTTP header configuration, and infrastructure stability. Server response optimization improves the speed at which Googlebot can fetch content, which raises the technical ceiling on crawl rate. Conditional request handling reduces the bandwidth cost per crawl request, which lets Googlebot allocate budget to more URLs. HTTP header configuration shapes how the indexing system processes the retrieved content, which connects retrieval to downstream stages. Infrastructure stability prevents the retry-and-throttle cycle that follows server errors.
Crawl budget management is a secondary leverage point that matters for large sites. Operators who deliberately exclude low-value URL patterns from crawl through robots.txt and canonical management redirect budget toward the URLs that actually need crawl attention. The discipline is meaningful at scale and academic for smaller sites where the budget exceeds the URL count.
The diagnostic discipline is the meta-leverage point that ties all the others together. Operators who can identify the specific crawl failure mode their site is experiencing apply the right intervention the first time. Operators who cannot diagnose specifically end up applying generic interventions that may not address the actual issue. The Search Console crawl reports, log file analysis, and URL Inspection tool are the diagnostic instruments that enable precision.
For more on the operational discipline that supports crawl-stage work as part of the broader SEO program, the Content discipline covers the content-side architecture and the Credibility discipline covers the authority-side architecture.
Verdict
The crawling stage is the discovery and retrieval layer of the Google Search pipeline. Discovery finds URLs to crawl through three pathways: linking, sitemaps, and direct submission. Retrieval fetches the content of discovered URLs through HTTP requests and processes the responses. Both functions have distinct failure modes and distinct intervention points, and operators who match interventions to functions produce sustained crawl coverage while operators who treat crawling as one undifferentiated activity often fix the wrong layer.
Discovery is dominated by linking on established sites. Internal linking produces the structural infrastructure that lets new content get discovered automatically without per-page intervention. External linking adds cross-domain discovery that exposes new URLs through third-party crawls. Sitemaps supplement linking with a hint mechanism that helps new content get discovered before inbound links accumulate. Direct submission is a precision tool for individual high-priority URLs but does not scale.
Retrieval depends on server health, response speed, conditional request handling, and HTTP header configuration. The function is where most technical SEO work actually happens. Operators who optimize retrieval mechanics expand the technical ceiling on crawl rate. Operators who let server errors, slow response times, or broken header configurations persist produce crawl impacts that take weeks to recover from once the underlying issue is fixed.
Crawl budget is the concept that describes how much crawler attention Google allocates to a site. The budget breaks across rate limit (the technical ceiling) and demand (Google’s interest in crawling). The budget primarily matters for large sites where coverage gaps appear. Most sites operate well below their budget and do not need active budget management, though the concept becomes operationally relevant at scale.
Robots directives shape crawl behavior through multiple layers: robots.txt at the path level, the robots meta tag at the page level, the X-Robots-Tag at the HTTP response level, and canonical and hreflang annotations that interact with the indexing stage. Each directive layer has specific semantics, and operators who confuse layers produce unintended outcomes. The directive layer is where careful reading of documentation pays off.
JavaScript rendering is the function that handles pages where content depends on client-side execution. Googlebot’s two-pass rendering model produces a delay between initial crawl and full content indexing for JavaScript-heavy pages. Sites that build for the rendering capabilities work well. Sites that ignore rendering and assume Googlebot sees what users see produce indexing problems that are hard to diagnose without understanding the layer.
The diagnostic discipline is what enables effective crawl-stage work. Discovery starvation, retrieval errors, robots.txt blocking, rendering breakdown, crawl budget waste, and canonical confusion are the recognizable failure patterns. Operators who can identify the specific failure mode apply the right intervention the first time. Operators who cannot end up applying generic SEO interventions that often do not address the actual issue.
For the broader pipeline framework, the pillar guide on How Google Search Works covers all four stages. The sibling articles on How Google Indexes Pages, How Google Ranks Search Results, and How Google Renders the SERP cover the stages that follow the crawl output downstream.
Frequently Asked Questions
What is the difference between crawling and indexing?
Crawling is the discovery and retrieval stage where Googlebot finds URLs and fetches their content. Indexing is the separate stage where Google evaluates the crawled content and decides whether to store it in the index. Crawling and indexing are different functions handled by different systems. A page can be crawled successfully but not indexed if it fails the quality evaluation at the indexing stage.
How does Googlebot find new pages on my site?
Googlebot finds new pages through three primary pathways: links from pages it already knows about, sitemaps submitted through Google Search Console, and direct URL submission via the URL Inspection tool. Internal linking from existing indexed content remains the most reliable discovery mechanism for sustained crawl coverage on an established site because it produces ongoing discovery without per-page intervention.
What is crawl budget and does it matter for my site?
Crawl budget is the amount of crawler attention Google allocates to a site, breaking across rate limit (the technical ceiling) and demand (Google’s interest in crawling). The concept primarily matters for large sites with hundreds of thousands of URLs where coverage gaps appear. Most sites operate well below their available budget and do not need active budget management. The exception is sites with faceted navigation, parameter URLs, or duplicate content patterns that consume crawl resources.
Should I use robots.txt or noindex to keep pages out of Google?
Use noindex, not robots.txt, to keep pages out of Google’s index. Robots.txt prevents crawling, which means Google cannot evaluate the page content and may still index the URL based on external signals like inbound links. The noindex directive operates at the indexing stage after crawling, which gives Google the explicit instruction to exclude the page. Operators who want to fully exclude content from search need to allow crawling and use noindex.
How long does it take for Googlebot to crawl a new page?
On an established site with consistent crawl frequency and good internal linking, Googlebot typically discovers and crawls new pages within 24 to 72 hours of publication. Sites with weaker crawl signals can take days or weeks. Operators who need faster crawling can submit URLs directly through the URL Inspection tool in Google Search Console, which usually triggers a crawl within hours.
Why is Googlebot crawling pages I do not want crawled?
Googlebot crawls URLs it has discovered through links, sitemaps, or external references. If pages are being crawled that should not be, the URLs are reaching Googlebot through one of those pathways. The fix depends on the source: remove internal links to the unwanted pages, remove them from sitemaps, and consider robots.txt directives if the URLs follow patterns that can be blocked at the path level. Crawl frequency on unwanted URLs typically decreases once the discovery pathways are addressed.
What is the two-pass rendering model?
The two-pass rendering model is how Google handles JavaScript-heavy pages. The first pass crawls the initial HTML response and indexes whatever content is present in the raw HTML. The second pass renders the page through a headless Chromium-based renderer, executes the JavaScript, and indexes the post-render DOM. The rendering pass happens asynchronously after the initial crawl, which produces a delay between initial crawl and full content indexing for pages that depend on JavaScript for primary content.
How do I know if Googlebot can render my JavaScript correctly?
Use the URL Inspection tool in Google Search Console and request a live test of the URL. The tool shows the rendered HTML that Googlebot produces, including how JavaScript-generated content appears after rendering. Comparing the rendered HTML to what users see in their browsers reveals whether the rendering function is producing the expected output. Significant differences indicate rendering problems that need investigation at the JavaScript or page architecture layer.
Why does Googlebot keep crawling 404 pages?
Googlebot recrawls 404 URLs periodically to verify the pages are still missing rather than temporarily unavailable. The behavior is normal and does not indicate a problem. Recrawl frequency on 404 URLs decreases over time as Googlebot becomes confident the pages are permanently gone. Returning 410 Gone instead of 404 Not Found signals permanent removal more strongly and reduces recrawl frequency faster, which is useful for URLs that will never come back.