How Google Search Works: Crawling, Indexing, Ranking, and Serving

AI Summary
What is this guide about? Google Search operates as a four-stage pipeline: crawling (discovering and fetching pages), indexing (evaluating and storing page content), ranking (ordering pages by relevance and quality for a query), and serving (assembling the final search results page with features, layout, and personalization). Each stage has its own logic, its own failure modes, and its own optimization levers.
What it is and who it is for: This guide is for SEO practitioners, site owners, and marketing teams who need to understand how Google processes web content from discovery through display. It covers how each stage works, where pages fail at each stage, and how operators can diagnose problems at the correct stage rather than applying generic fixes that miss the actual issue.
The rule: SEO problems have stages. A page not appearing in search results could be failing at crawling, indexing, ranking, or serving, and each failure requires a different intervention. Operators who diagnose the stage before designing the fix produce results that generic optimization cannot match.
Google Search Is a Pipeline, Not a Single Algorithm
The most common misconception about Google is that a single algorithm reads a page and decides where it ranks. The reality is a sequential pipeline where each stage performs a distinct function and passes its output to the next stage. A page must survive each stage in order to appear in search results. Failure at any stage removes the page from the pipeline entirely, regardless of how strong it would have scored at subsequent stages.
The four stages are crawling, indexing, ranking, and serving. Crawling discovers and fetches pages. Indexing evaluates and stores them. Ranking orders them for specific queries. Serving assembles them into the results page the user sees. The stages are not parallel. They are sequential. A page that fails at crawling never reaches indexing. A page that fails at indexing never reaches ranking. A page that ranks well can still fail at serving if it is excluded from the SERP features that dominate the results page.
Understanding the pipeline is the diagnostic framework that separates effective SEO from guesswork. When a page is not performing, the first question is not “what should I optimize?” The first question is “at which stage is this page failing?” The answer determines everything that follows, because the interventions for each stage are fundamentally different.
This guide covers each stage in summary. The operational deep-dives live in the four tier articles linked from each section. The broader disciplines that support pipeline optimization, content architecture and credibility infrastructure, are where the strategic work compounds across all four stages simultaneously.
Stage One: Crawling
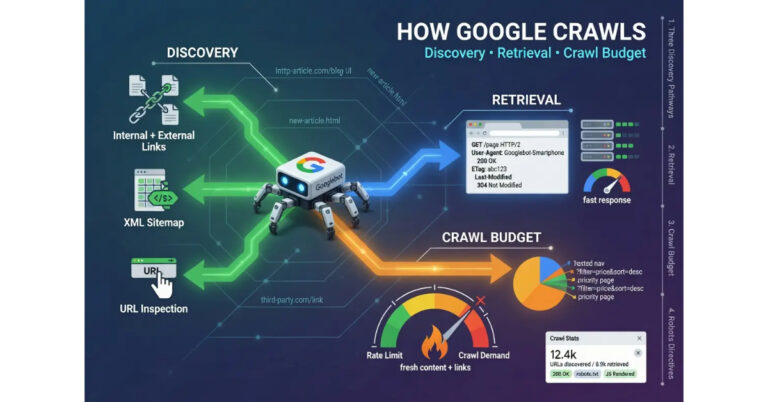
Crawling is how Google discovers that a page exists and retrieves its content. Googlebot, Google’s web crawler, follows links across the web, reads sitemaps, and processes URL submissions from Search Console to build a continuously updated map of what exists online. When Googlebot arrives at a URL, it requests the page from the server and downloads the HTML, CSS, JavaScript, and other resources needed to understand the content.
The crawling stage has two functions that fail independently. Discovery is whether Googlebot finds the URL at all. A page with no inbound links, no sitemap entry, and no Search Console submission is invisible to the crawler. It exists on the web but Google does not know it is there. Retrieval is whether Googlebot can successfully fetch the content once it finds the URL. Server errors, slow response times, robots.txt blocks, and incomplete responses all produce retrieval failures where the URL was discovered but the content was not obtained.
Crawl budget is the operational constraint most sites never think about and large sites cannot ignore. Google allocates a crawl budget to each domain based on the site’s server capacity and the perceived value of crawling it. Sites with thousands of pages and slow servers may find that Googlebot cannot crawl all their pages within the allocated budget, meaning some pages go weeks or months between crawls. For smaller sites with fast servers, crawl budget is effectively unlimited and not a practical concern.
The levers operators control at the crawling stage are sitemap maintenance, internal linking architecture, server response speed, and robots.txt configuration. Sitemaps give Googlebot a direct URL list. Internal links create discovery pathways that do not depend on sitemap processing. Fast server responses protect crawl budget. Robots.txt prevents Googlebot from wasting crawl budget on URLs that should not be indexed.
For the full operational treatment of how crawling works, crawl budget management, and diagnosing crawl failures in Search Console, the tier article on How Google Crawls the Web covers the complete guide.
Stage Two: Indexing
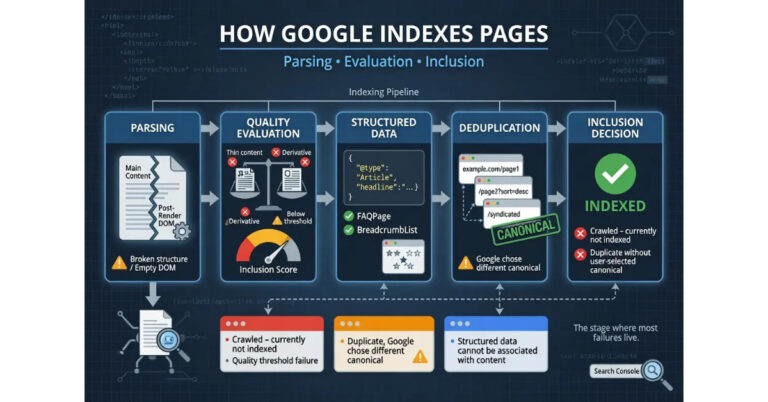
Indexing is where Google evaluates the crawled content and decides whether it deserves a spot in the search index. Not every crawled page gets indexed. Google runs the content through a quality evaluation that considers uniqueness, depth, accuracy, and whether the page adds something to the index that existing pages do not already cover. Pages that fail this evaluation appear in Search Console as “Crawled, currently not indexed,” which is the single most common indexing failure operators encounter.
The indexing stage processes several things simultaneously. Content analysis extracts the topics, entities, and semantic relationships from the page content. Duplicate detection compares the page against existing index entries to identify whether it is substantially similar to content already indexed. Canonical evaluation determines which URL should represent the content when multiple URLs contain similar or identical material. Directive processing reads meta robots tags and X-Robots-Tag headers to determine whether the page has been excluded from indexing by the operator.
The quality threshold is the gate most pages fail at, and the threshold has risen significantly in the last two years. The web is producing more content than ever, much of it AI-generated, and Google’s index has limited capacity. The indexing system is increasingly selective about what it includes, favoring content that demonstrates genuine E-E-A-T signals, covers topics with original depth rather than restating existing coverage, and comes from domains with established topical authority.
Structured data gets processed at the indexing stage even though its effects are most visible at the serving stage. Schema markup tells Google’s systems what type of content the page contains, who authored it, what organization published it, and how the content relates to broader entities. The markup does not influence whether the page gets indexed, but it determines what enhanced features the page is eligible for once it reaches the serving stage.
For the full operational treatment of indexing evaluation, quality thresholds, canonical management, and diagnosing “not indexed” status in Search Console, the tier article on How Google Indexes Pages covers the complete guide.
Stage Three: Ranking
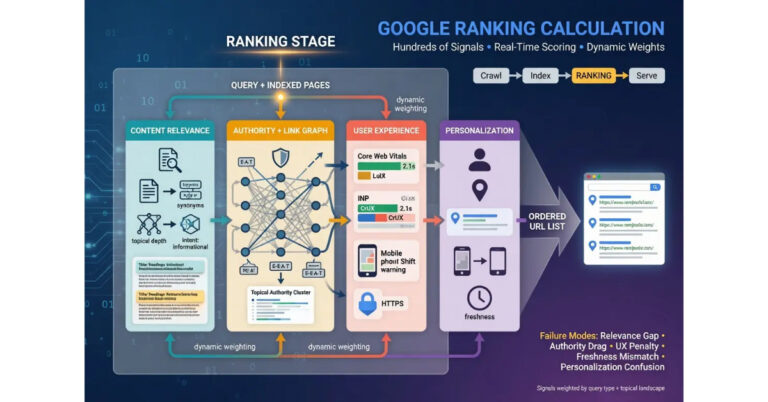
Ranking is the stage most people think of when they think of SEO. A user enters a query. Google’s ranking systems evaluate every indexed page that could potentially answer that query and produce an ordered list based on relevance, quality, and user experience signals. The page that scores highest appears first. The ordering determines which pages get seen and which pages exist in the index but never reach a human eye.
The ranking evaluation is not a single algorithm. It is a collection of systems that each evaluate different dimensions of the page and the query. Some systems evaluate textual relevance, matching the query terms against the page content. Some evaluate link-based authority signals, measuring the quality and quantity of other sites that reference the page. Some evaluate user experience signals, including page load speed, mobile usability, and Core Web Vitals. Some evaluate freshness, determining whether the content is current enough for queries where recency matters.
The systems produce scores that get combined into the final ranking order. The combination is not a simple weighted average. Different systems carry different weight depending on the query type. A query about today’s news weights freshness heavily. A query about a medical condition weights E-E-A-T signals heavily. A query about a specific product weights user experience and transactional signals heavily. The ranking calculation adapts to the query, which is why the same page can rank differently for queries that seem similar but carry different intent.
The competitive dimension of ranking is what makes it the hardest stage to optimize. Crawling and indexing are largely about meeting technical thresholds. Ranking is about outperforming every other indexed page that targets the same query. The quality bar is not fixed. It is set by the competition. A page that would rank first in a low-competition niche might not crack the top 50 for a competitive commercial keyword, not because the page is bad, but because the competing pages are stronger on the signals the ranking systems evaluate.
The levers operators control at the ranking stage are on-page optimization, internal linking for topical authority, backlink development, content depth, and user experience optimization. Each lever maps to a specific ranking system. On-page optimization serves the relevance systems. Internal linking serves topical authority. Backlinks serve the authority systems. Content depth serves the quality evaluation. User experience optimization serves Core Web Vitals and engagement signals.
For the full operational treatment of how ranking systems work, which signals carry the most weight, and how to diagnose ranking failures, the tier article on How Google Ranks Search Results covers the complete guide.
Stage Four: Serving
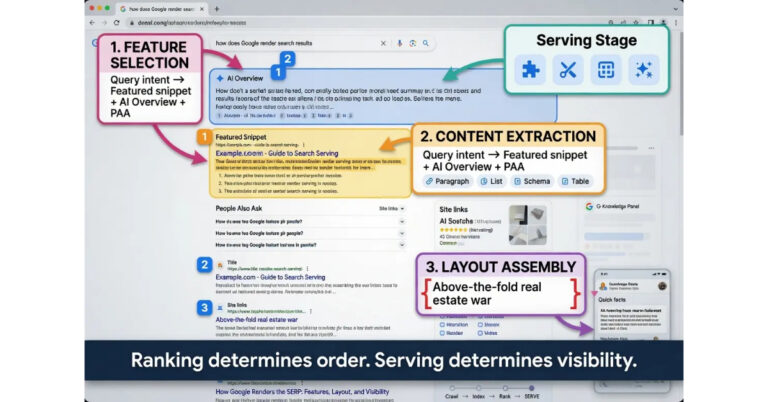
Serving is the final stage where the ranked list of URLs gets transformed into the actual search results page users see. This stage is often invisible to operators because it happens between the ranking calculation and the rendered page, but it has its own logic and its own impact on whether ranked pages actually deliver the visibility operators expect.
The serving stage performs four functions. Feature selection decides which SERP features to show for the query: featured snippets, People Also Ask boxes, image packs, video carousels, knowledge panels, local packs, AI Overviews. Content extraction pulls specific content elements from pages to populate those features. Layout assembly arranges the features and organic results into the final page. Personalization applies location, device, and user history signals to adjust the final presentation.
The serving stage is where AI Overviews enter the picture. When Google generates an AI Overview for a query, it synthesizes content from multiple sources and displays it above the organic results. The sources cited in AI Overviews are not always the same pages that rank highest organically. A page ranked fifth can be cited in the AI Overview while the page ranked first is excluded. This creates a second layer of search visibility that operates on overlapping but distinct criteria from organic ranking.
The serving stage is also where structured data investment pays off. Rich results, enhanced listings with review stars, FAQ dropdowns, how-to steps, and other visual enhancements, are determined at the serving stage based on the structured data processed during indexing. A page with valid schema markup and strong organic ranking can appear with enhanced features that dramatically increase its click-through rate compared to a plain blue link at the same position.
For the full operational treatment of SERP features, content extraction, layout assembly, and how to optimize for the serving stage, the tier article on How Google Renders the SERP covers the complete guide.
Where Each Stage Fails
Each stage has distinct failure modes, and operators who diagnose at the wrong stage waste effort on interventions that cannot fix the actual problem.
Crawling failures are discovery failures (Googlebot cannot find the URL) or retrieval failures (Googlebot finds the URL but cannot fetch the content). The symptoms in Search Console are URLs that never appear in the coverage report or URLs that show server errors during crawl attempts. The fixes are sitemap updates, internal linking improvements, server response optimization, and robots.txt auditing.
Indexing failures are quality threshold failures (the page was crawled but did not score high enough for inclusion), duplicate content failures (the page was deduplicated against another URL), or technical directive failures (meta robots or X-Robots-Tag blocked indexing). The most common symptom is “Crawled, currently not indexed” in Search Console. The fixes are content quality improvement, canonical management, and directive auditing.
Ranking failures happen when pages are indexed but do not appear in competitive positions. The causes are insufficient relevance signals, insufficient authority signals, topical authority gaps, or user experience problems. The fixes are on-page optimization, content gap analysis, backlink development, and Core Web Vitals improvement.
Serving failures happen when pages rank well but do not appear with the visibility operators expect. Featured snippet exclusion, rich result loss, AI Overview omission, and local pack exclusion are all serving-stage failures. The fixes are structured data optimization, content structure adjustments for feature extraction, and entity authority building.
The diagnostic discipline is to identify the failure stage before designing the intervention. A page not appearing in search has a different fix depending on whether the problem is at crawling, indexing, ranking, or serving. Operators who skip the diagnostic step and apply generic SEO interventions often spend months on the wrong fix.
Operator Leverage Points
The leverage points for SEO operators differ across the four stages. Matching interventions to stages is what produces results that diffuse effort cannot match.
Crawling leverage: sitemap maintenance, internal link architecture, server response optimization, robots.txt configuration, crawl budget management for larger sites.
Indexing leverage: content quality investment, structured data implementation, canonical management, indexability directive auditing. Content quality is the dominant lever because the quality threshold is what most “not indexed” failures hit.
Ranking leverage: on-page optimization, internal linking for topical authority through content clusters, backlink architecture, Core Web Vitals optimization, and topical depth investment. The topical depth lever is the long-horizon play that builds domain-level credibility across entire subject areas.
Serving leverage: structured data for rich result targeting, content structure optimization for featured snippet extraction, entity association for knowledge graph eligibility, and click-through rate optimization through title and description tuning.
The operator who works across all four stages produces results that operators working at one or two stages cannot match. The pipeline framework is what enables this multi-stage approach. Operators who think of SEO as one undifferentiated activity miss the precision that four-stage decomposition provides.
The AI Layer on Top of the Pipeline
In 2026, the four-stage pipeline has a fifth consideration that sits on top of the serving stage: AI-generated responses. Google AI Overviews, ChatGPT, Perplexity, and other AI platforms now synthesize answers from web content and present them directly to users, often before the user reaches the organic results.
The AI layer evaluates sources differently from the organic ranking systems. Content structure, extractability, entity authority, and trust signals carry different weight in AI source selection than in organic ranking. A page can rank first organically and be absent from the AI Overview. A page on page two can be the primary source the AI cites. The two systems overlap but are not interchangeable.
Understanding the traditional four-stage pipeline remains foundational because the AI layer draws from the same indexed web that the pipeline produces. Pages that fail at crawling or indexing cannot be cited by AI systems because they do not exist in the sources those systems access. Pages that succeed through all four stages and are also optimized for AI extractability occupy both layers of search visibility simultaneously.
For the full treatment of how AI search visibility works, how to measure it, and how to optimize for it alongside traditional search, the AI Search Visibility pillar covers the complete framework.
Verdict
Google Search is a four-stage pipeline: crawl, index, rank, serve. Each stage has its own evaluation logic, its own failure modes, and its own optimization levers. The stages are sequential. Failure at any stage removes the page from every subsequent stage.
The diagnostic framework that produces results is to identify which stage a page is failing at before designing the intervention. Crawling problems need discovery and retrieval fixes. Indexing problems need quality and canonical fixes. Ranking problems need relevance, authority, and user experience fixes. Serving problems need structured data and feature-targeting fixes. Applying the wrong fix to the wrong stage wastes time and budget without improving outcomes.
The deeper treatment of each stage lives in the four tier articles. The article on How Google Crawls the Web covers discovery, retrieval, and crawl budget. The article on How Google Indexes Pages covers quality evaluation, canonicalization, and index inclusion. The article on How Google Ranks Search Results covers ranking systems, authority signals, and competitive positioning. The article on How Google Renders the SERP covers feature selection, content extraction, and layout assembly.
FAQ
How does Google Search actually work?
Google Search operates as a four-stage pipeline. Crawling discovers and fetches web pages through Googlebot. Indexing evaluates the content and decides whether to store it in the search index. Ranking orders indexed pages by relevance and quality when a user enters a query. Serving assembles the final results page with organic listings, SERP features, and AI Overviews. A page must pass each stage sequentially to appear in search results.
What is the difference between crawling and indexing?
Crawling is Google discovering that a URL exists and downloading its content. Indexing is Google evaluating that content and deciding whether it meets the quality threshold for inclusion in the search index. A page can be crawled successfully and still fail at indexing if the content does not pass the quality evaluation. “Crawled, currently not indexed” in Search Console means the page passed crawling but failed at indexing.
Why is my page not showing up in Google search results?
The answer depends on which pipeline stage the page is failing at. If the page does not appear in Search Console’s coverage report, it has a crawling problem. If it shows “Crawled, currently not indexed,” it has an indexing quality problem. If it is indexed but ranks beyond page one, it has a ranking problem. If it ranks well but is not visible in SERP features or AI Overviews, it has a serving problem. Diagnosing the correct stage determines the correct fix.
What are Google ranking factors?
Google’s ranking systems evaluate multiple dimensions including textual relevance to the query, link-based authority signals from other websites, user experience signals like page speed and mobile usability, content freshness for time-sensitive queries, and E-E-A-T signals that measure expertise, experience, authoritativeness, and trust. Different signals carry different weight depending on the query type.
How long does it take Google to index a new page?
Indexing timelines range from hours to weeks depending on the site’s crawl frequency, server speed, content quality, and domain authority. New sites with no established crawl patterns typically wait longer than established sites with regular crawl schedules. Submitting a URL through Google Search Console can accelerate discovery but does not guarantee indexing if the content does not pass the quality threshold.
Does ranking on Google guarantee visibility in AI Overviews?
No. Google AI Overviews select sources based on criteria that overlap with but differ from organic ranking factors. Content structure, extractability, and source trustworthiness for specific claims carry more weight in AI Overview citation than in organic ranking. A page can rank first organically and be absent from the AI Overview, while a lower-ranking page with more extractable content gets cited instead.