How Google Indexes Pages: Parsing, Evaluation, and Inclusion
AI Summary
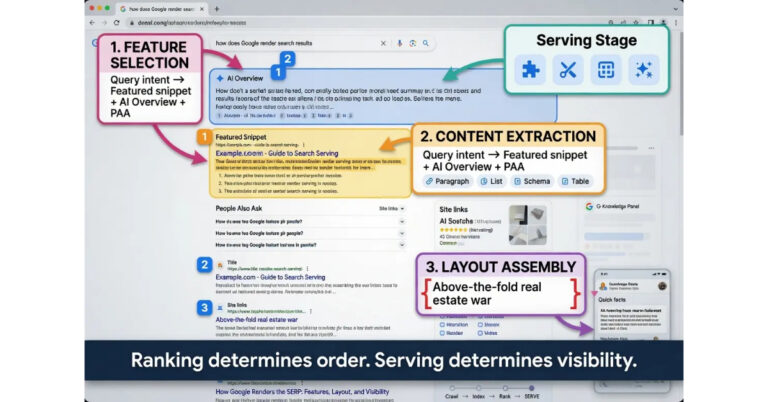
What is the indexing stage? Indexing is where Google decides whether a crawled page belongs in the search index. The stage runs as a sequence of functions: parsing the crawled HTML, evaluating quality signals, processing structured data, deduplicating against existing indexed content, and making the final inclusion decision. Each function can produce a different failure mode, and the failures are where most “crawled but not indexed” outcomes actually live.
What it is and who it is for: The indexing stage matters for any operator who has pages that crawl successfully but never appear in search results. The stage is the second of four in the Google Search pipeline, and pages that fail at indexing cannot reach the ranking or serving stages regardless of how strong the content’s authority signals are.
The rule: Indexing is not automatic after crawling. Most indexing failures are quality-threshold failures, not technical failures. Operators who confuse the two often spend months fixing the wrong layer.
Table of Contents
Parsing and Quality Evaluation
The indexing stage begins with parsing. Once Googlebot delivers crawled content to the indexing pipeline, the parser extracts the meaningful elements from the raw HTML. The parser identifies the main content area, separates it from navigation and boilerplate, processes the structured data markup, and produces a clean representation of what the page actually contains. The parser handles JavaScript-rendered content through a separate rendering layer that executes the page’s JavaScript and produces the post-render DOM, which then gets re-parsed.
The parsing function is largely invisible to operators because it produces no visible output until the next function flags an issue. A page that parses cleanly proceeds to evaluation. A page that does not parse cleanly may produce indexing issues that look like quality failures but actually originate at the parsing layer. The most common parsing-layer problems involve broken HTML structure that confuses the parser about where the main content begins, JavaScript rendering breakdowns that produce empty or malformed post-render DOM, and content that loads through patterns the renderer cannot trigger.
Quality evaluation is the function where most indexing failures actually occur. The evaluation system scores the parsed content against signals including content uniqueness, depth of coverage, technical health, internal linking patterns, and the perceived value of adding the page to the index relative to similar content already there. The score determines whether the page passes the inclusion threshold. Pages that score above the threshold get indexed. Pages that score below get the “Crawled – currently not indexed” status that operators see in Google Search Console.
The threshold is not fixed. The bar shifts based on the topical landscape, the volume of similar content already indexed, and the authority of the publishing domain. A page that would have indexed easily in a niche with few competitors might fail to index in a saturated topical area where Google has thousands of similar pages. The same page on a high-authority domain might pass the threshold that the same content on a low-authority domain would fail. Operators who diagnose indexing failures need to consider the threshold dynamics, not just the absolute quality of the individual page.
Content uniqueness is the heaviest weighted signal in quality evaluation. Pages that closely resemble other content already in the index face higher rejection rates because Google does not need duplicate or near-duplicate coverage of topics it already has well-indexed. Uniqueness is evaluated at the substantive level, not just the textual level. A page that paraphrases existing content with different wording but the same information density and structural pattern often gets evaluated as derivative even when no specific sentence appears verbatim elsewhere.
Depth of coverage is the second major weight. Pages that comprehensively address their topic with substantive detail score higher than pages that touch the topic shallowly. The evaluation considers what users searching for the topic would expect to find, what questions the page answers, and whether the coverage demonstrates expertise or surface familiarity. The depth signal is what produces the documented gap between thin AI-generated content and substantive long-form content even when both are technically grammatical and on-topic.
The honest read on parsing and evaluation is that the layer is where content quality actually matters operationally. Operators who think of quality as an abstract concept miss that the evaluation is a concrete scoring function that weights specific signals. Operators who design content for the evaluation produce pages that index reliably. Operators who do not often have content that they consider high quality but the evaluation function scores below the threshold for reasons that are diagnosable but not visible without understanding the layer.
For more on the upstream stage that delivers content to the indexing pipeline, the tier article on How Google Crawls the Web covers the crawl mechanics. The pillar guide on How Google Search Works covers the four-stage pipeline. The sibling articles on How Google Ranks Search Results and How Google Renders the SERP cover the downstream stages.
Structured Data Processing
Structured data processing happens in parallel with quality evaluation during the indexing stage. The system reads the JSON-LD, microdata, and RDFa markup on the page and uses it to enrich the indexed record with structured information about entities, relationships, and content types. The function does not directly determine whether a page gets indexed, but it determines whether an indexed page becomes eligible for rich result formats at the serving stage.
JSON-LD is the format Google strongly prefers for structured data. The format embeds structured data as JSON in a script tag in the page head, separated from the visible HTML content. JSON-LD is easier for the indexing system to parse reliably than inline markup formats because it does not require the system to associate structured data attributes with specific HTML elements. Operators who use microdata or RDFa can produce valid structured data, but JSON-LD is the format Google’s documentation pushes and the format that most consistently produces the expected outcomes.
The structured data types that matter for SEO include Article for editorial content, FAQPage for question-and-answer formats, HowTo for procedural content, Product for e-commerce listings, BreadcrumbList for site navigation hierarchy, Organization for entity disambiguation, and Person for author authority. Each type unlocks specific rich result formats at the serving stage. Article markup combined with publisher and author information enables enhanced search appearance in news and editorial contexts. FAQPage markup enables question-answer rich results that expand directly in the SERP. BreadcrumbList markup enables the breadcrumb navigation display that replaces raw URL strings in search results.
The processing function evaluates structured data validity before accepting it. Markup that does not validate against the schema specification gets ignored. Markup that contradicts the visible page content gets flagged as potentially manipulative. Markup that claims content the page does not actually contain produces the “structured data cannot be associated with content” warnings that appear in Google Search Console. The validation is strict enough that operators who copy structured data examples without adapting them to the actual page content often produce invalid markup.
The relationship between structured data and indexing is asymmetric. Pages without structured data still get indexed. Pages with structured data do not get indexed faster or evaluated more favorably purely because of the markup. The structured data benefit shows up at the serving stage where rich result eligibility produces visible SERP advantages. Operators who treat structured data as an indexing signal misunderstand what the markup actually does. Operators who treat it as a serving-stage eligibility mechanism use it correctly.
The honest read on structured data processing is that the function is high-leverage but only for the right purposes. Pages that need to compete for SERP feature placement benefit substantially from valid structured data. Pages that are not eligible for any rich result format gain nothing from adding markup. The discipline is to identify which structured data types apply to each page type on the site and implement them correctly, rather than adding generic schema indiscriminately.
Deduplication and Canonical Selection
Deduplication is the function that decides what to do when multiple URLs contain substantially similar content. The indexing system identifies the canonical version among duplicates and indexes that version while excluding the others from active indexing. The function operates on similarity calculations that consider not just the visible content but the structural patterns, the metadata, and the relationships between URLs. Operators who manage canonicalization correctly preserve the index slot for their preferred URL. Operators who do not lose index slots to whichever URL the system selects.
The canonical signals that the deduplication function considers come from multiple sources. The explicit canonical link annotation in the HTML head is the operator’s direct instruction about which URL should be canonical. Internal linking patterns contribute signal because the system reads which URL the site itself links to most consistently. Redirect chains contribute signal because pages that redirect to a target URL are implicitly endorsing that URL as canonical. Sitemap entries contribute signal because operators who include specific URLs in sitemaps are signaling those URLs as preferred. Content similarity calculations contribute signal because the system weighs the signals against the actual content overlap.
The canonical decision is the system’s call, not the operator’s. The explicit canonical annotation is treated as a hint, not a directive. Google reserves the right to override the operator’s canonical preference when other signals strongly contradict it. The most common scenario is when the operator declares canonical to URL A but internal linking, redirect chains, and external links all point at URL B. The system selects URL B as canonical despite the explicit annotation, which produces the “Duplicate, Google chose different canonical than user” status in Search Console.
The duplicate content concept is more nuanced than operators sometimes realize. Pure duplicates with identical content are easy cases. The harder cases involve near-duplicates where the same product appears with slight variations across URLs, the same article appears on multiple syndication partners, or the same content appears at different URL parameters. The system has to decide whether each variation deserves its own index entry or whether one canonical version should absorb the others. The decisions vary by signal strength and topical context.
Cross-domain canonicalization is the most underappreciated dimension of the function. When the same content appears on multiple domains through legitimate syndication, the system identifies the original publisher and treats the syndicated copies as duplicates that defer to the original. Operators who syndicate content without proper canonical signals back to the original can lose the canonical decision to the syndicating partner if that partner has stronger authority signals. The defensive move is to use rel=canonical pointing back to the original URL on every syndicated copy, which preserves the canonical claim regardless of where the syndicated version appears.
The honest read on deduplication is that the function is doing more work than most operators realize, and the work happens invisibly until something goes wrong. Pages that should rank for their target queries but do not are sometimes losing the canonical decision to a different URL the operator did not intend. The diagnosis requires checking Search Console for canonical inconsistency status and tracing through the various signals to identify why the system is selecting a different URL than the operator declared. The fix usually involves aligning the signals across all the layers, which means updating internal links, redirect chains, sitemap entries, and external link targets to consistently endorse the same canonical URL.
Where Indexing Actually Fails
Indexing failures break across recognizable patterns, and operators who can identify the specific failure mode can apply the targeted intervention. The diagnosis matters because the failures look similar from the outside but require different fixes depending on which function actually broke.
The first failure pattern is the quality threshold failure. The page is crawled, parsed, and evaluated, but the evaluation score falls below the inclusion threshold. The pattern shows up in Search Console as “Crawled – currently not indexed” status. The root causes include thin content that does not meet the depth signal, derivative content that triggers the uniqueness signal, content on topics already saturated in the index, and content on domains lacking sufficient authority for the topical area. The fix is content-side: more substantive depth, more original analysis, more evidence of expertise, or topical focus on areas where the domain has stronger authority.
The second failure pattern is the duplicate content failure. The page is crawled and evaluated favorably, but the deduplication function identifies it as substantially similar to another URL and selects the other URL as canonical. The pattern shows up in Search Console as “Duplicate without user-selected canonical,” “Duplicate, Google chose different canonical than user,” or “Duplicate, submitted URL not selected as canonical” status. The root causes include genuine duplicate content across multiple URLs, near-duplicate content that the system flagged as duplicate, syndication without proper canonical signals, and faceted navigation generating URL variants. The fix is canonical management: explicit canonical annotations, consolidated internal linking, redirect implementation for true duplicates, and noindex directives for variants that should not compete for index slots.
The third failure pattern is the technical directive failure. The page is crawled and evaluated favorably, but a technical directive tells the indexing system to exclude the page. The pattern shows up in Search Console as “Excluded by ‘noindex’ tag” or “Page with redirect” status. The root causes include unintended noindex meta tags carried over from staging environments, X-Robots-Tag headers misconfigured at the server level, and redirect chains that the operator did not realize were active. The fix is technical: audit the page for noindex tags, audit the HTTP response for restrictive headers, and verify the URL serves the expected response without unexpected redirects.
The fourth failure pattern is the rendering failure. The page is crawled but the rendering layer cannot produce a usable post-render DOM, which means the indexing system has no substantive content to evaluate. The pattern shows up as pages with sparse indexed content despite users seeing rich content in browsers. The root causes include JavaScript errors during rendering, dependencies on user state that Googlebot does not have, content that loads only after user interactions, and lazy-loading patterns the renderer cannot trigger. The fix involves the JavaScript layer: server-side rendering for critical content, proper lazy-loading patterns, and removal of dependencies that block content visibility for the renderer.
The fifth failure pattern is the discovered-not-yet-indexed status. The page is in Google’s queue but has not been processed yet. The pattern shows up in Search Console as “Discovered – currently not indexed” status. The status is normal for new URLs and clears as the indexing system gets to them. Status that persists for weeks or months indicates the URL is queued at low priority, often because the domain has weak crawl signals or the URL discovery pathway is providing weak importance signals. The fix is to strengthen the discovery signal, often through better internal linking from established pages or external links from authoritative sources.
The honest read on indexing failures is that the diagnosis determines the intervention. Operators who confuse quality threshold failures with technical directive failures spend effort on the wrong layer. Operators who confuse duplicate content failures with rendering failures produce no improvement because they are fixing a different function than the one that actually broke. The Search Console URL Inspection tool combined with careful reading of the specific status code is the diagnostic instrument that enables precision.
Operator Leverage Points at the Indexing Stage
The leverage points for operators at the indexing stage break across the major functions of the stage: quality evaluation, structured data, and canonical management. Each function has interventions that act on it directly and other interventions that affect it indirectly through related stages.
Quality evaluation leverage points include content depth investment, originality discipline, topical focus, and author infrastructure. Content depth investment is the dominant lever because the depth signal is what most quality threshold failures hit. Originality discipline produces content that scores favorably on the uniqueness signal. Topical focus concentrates production on areas where the domain has accumulating authority, which raises the threshold the same content needs to clear. Author infrastructure with named authors, surfaced bios, and credential signals contributes to the broader credibility evaluation that interacts with quality scoring.
Structured data leverage points include systematic implementation across page types, validation discipline, and feature-specific targeting. Systematic implementation means every page type on the site has the appropriate structured data type applied consistently rather than markup added piecemeal to individual pages. Validation discipline means testing structured data through the Rich Results Test before publishing and addressing any errors that surface. Feature-specific targeting means choosing which rich result formats the page should be eligible for and implementing the structured data that unlocks those specific features.
Canonical management leverage points include explicit canonical annotations, internal linking consistency, redirect architecture, and sitemap precision. Explicit canonical annotations on every page give the system the operator’s direct instruction. Internal linking consistency aligns the implicit signals with the explicit annotation. Redirect architecture handles URL variants by consolidating them onto the canonical URL through 301 redirects rather than letting them coexist as duplicates. Sitemap precision ensures only canonical URLs appear in sitemaps, which adds another consistent signal to the canonical decision.
The diagnostic discipline ties the leverage points together. Operators who can identify which indexing function is failing apply the right intervention the first time. Operators who cannot diagnose specifically often spend months on generic interventions that do not address the actual issue. The Search Console Coverage report, the URL Inspection tool, and the Rich Results Test are the diagnostic instruments that enable precision.
For more on the operational disciplines that support indexing-stage work as part of the broader SEO program, the Content discipline covers the content-side architecture and the Credibility discipline covers the authority-side architecture.
Verdict
The indexing stage is the evaluation and inclusion layer of the Google Search pipeline. The stage runs as a sequence of functions: parsing the crawled HTML, evaluating quality signals, processing structured data, deduplicating against existing indexed content, and making the inclusion decision. Each function has distinct failure modes and distinct intervention points, and operators who match interventions to functions produce indexing outcomes that operators treating indexing as one undifferentiated activity cannot reliably produce.
Quality evaluation is where most indexing failures actually occur. The function scores parsed content against signals including content uniqueness, depth of coverage, technical health, internal linking patterns, and the perceived value of adding the page to the index relative to similar content already there. The threshold is dynamic, shifting based on topical landscape and domain authority. Pages that score below the threshold get the “Crawled – currently not indexed” status that operators frequently misdiagnose as a technical problem when it is actually a content-quality problem.
Structured data processing operates in parallel with quality evaluation. The function reads structured data markup and enriches the indexed record with entity, relationship, and content-type information. The benefit shows up at the serving stage where structured data unlocks rich result eligibility. Pages without structured data still get indexed, and pages with structured data do not get indexed faster, but the markup determines which rich result formats become available downstream.
Deduplication and canonical selection decide what to do when multiple URLs contain similar content. The function uses signals from explicit canonical annotations, internal linking patterns, redirect chains, sitemap entries, and content similarity calculations. The canonical decision is the system’s call, and explicit annotations are hints rather than directives. Operators who align all the canonical signals consistently preserve their preferred canonical URL. Operators who do not lose canonical decisions to whichever URL the system selects based on the conflicting signals.
The failure patterns at the indexing stage are diagnosable. Quality threshold failures, duplicate content failures, technical directive failures, rendering failures, and discovered-not-yet-indexed status each have specific Search Console signatures and specific fixes. Operators who diagnose specifically apply the right intervention the first time. Operators who do not often spend months on generic SEO improvements that cannot fix the actual failure point because the failure lives at a different function than the changes target.
The leverage points for operators include content depth investment, originality discipline, topical focus, structured data implementation, canonical management, and the diagnostic discipline that ties them together. The interventions are specific to the indexing stage rather than generic SEO improvements, which is what produces results that broad SEO effort does not reliably produce.
For the broader pipeline framework, the pillar guide on How Google Search Works covers all four stages. The sibling articles on How Google Crawls the Web, How Google Ranks Search Results, and How Google Renders the SERP cover the stages that surround the indexing function in the pipeline.
Frequently Asked Questions
Why is my page crawled but not indexed?
The “Crawled – currently not indexed” status means Googlebot fetched the page successfully but the indexing system’s quality evaluation scored the page below the inclusion threshold. The most common causes are thin content that does not meet the depth signal, derivative content that triggers the uniqueness signal, content on saturated topics, and content on domains that lack sufficient authority for the topical area. The fix is content-side rather than technical: more substantive depth, more original analysis, and more evidence of expertise.
Does adding structured data help my page get indexed?
No. Structured data does not affect whether a page gets indexed or how favorably the indexing system evaluates the content. The benefit shows up at the serving stage where structured data unlocks rich result eligibility. Pages without structured data still get indexed normally, and pages with structured data do not get indexed faster or scored higher purely because of the markup.
What is the difference between robots.txt blocking and a noindex tag?
Robots.txt blocks crawling at the path level, which means Googlebot cannot fetch the URL and the indexing system cannot evaluate the content. The noindex meta tag operates at the indexing layer after crawling, which gives Google the explicit instruction to exclude the page from the index. To fully exclude content from search, use noindex with crawling allowed. Robots.txt blocking can leave URLs in the index based on external link signals because Google cannot crawl the page to see the noindex directive.
Why did Google choose a different canonical than the one I declared?
The explicit canonical annotation is treated as a hint, not a directive. Google evaluates multiple canonical signals: the explicit annotation, internal linking patterns, redirect chains, sitemap entries, and content similarity calculations. When the signals conflict, the system selects the canonical URL based on the strongest aggregate signal. The fix is to align all the canonical signals consistently, which usually means updating internal links, redirect targets, and sitemap entries to match the explicit canonical declaration.
How does Google handle duplicate content across multiple URLs?
The deduplication function identifies near-duplicates and selects one URL as canonical, indexing that URL while excluding the others from active indexing. The selection considers explicit canonical annotations, internal linking patterns, redirect chains, sitemap entries, and content similarity calculations. Operators who manage canonicalization correctly preserve their preferred URL as canonical. Operators who do not lose canonical decisions to whichever URL accumulates stronger signals.
Should I use JSON-LD or microdata for structured data?
Use JSON-LD. Google’s documentation strongly prefers it, and the indexing system parses JSON-LD more reliably than inline microdata or RDFa. JSON-LD embeds the structured data as JSON in a script tag in the page head, separated from the visible HTML, which makes it easier for the system to parse without needing to associate attributes with specific HTML elements. Microdata and RDFa can produce valid structured data but introduce parsing complexity that JSON-LD avoids.
Why does my page index for some queries but not others?
Pages that are indexed remain eligible to rank for any query, but the ranking calculation determines which queries produce visibility. A page that does not appear for specific queries is usually losing the ranking calculation rather than failing to be indexed. The diagnostic distinction matters because the fix differs: indexing failures require content quality work, while ranking failures require relevance, authority, or user experience work depending on which signal is weakest for the target query.
How long should I wait before troubleshooting an indexing issue?
For new pages on an established site, wait 7 to 14 days before treating the absence from the index as a problem. The indexing pipeline is not instantaneous, and “Discovered – currently not indexed” is a normal transient status during the queue period. Status that persists beyond two weeks suggests an actual indexing problem that warrants diagnosis through the URL Inspection tool. Pages that have been published for more than 30 days without being indexed almost always have a specific failure pattern that needs identification.
Can low-quality pages on my site hurt the indexing of good pages?
Yes, indirectly. Quality evaluation considers domain-level signals alongside page-level signals, and sites with large amounts of thin or duplicate content can produce a domain quality signature that makes individual pages harder to index even when those specific pages are substantive. The fix is site-level: prune or improve thin content, consolidate duplicate URLs, and ensure the domain’s overall content base demonstrates the quality the operator wants individual pages to be evaluated against.