
AI Content at Scale: Production Systems Without the Penalty Risk
AI Summary
What is AI content at scale? AI content at scale is the production approach where operators use AI to multiply content throughput without sliding into the volume play that the helpful content framework specifically targets. The approach exists, works, and is more disciplined than most operators initially expect.
What it is and who it is for: The scale architecture matters for any operator who needs to publish more than a few articles per week. The patterns that fail at small scale fail catastrophically at large scale, and the patterns that work require deliberate operational design.
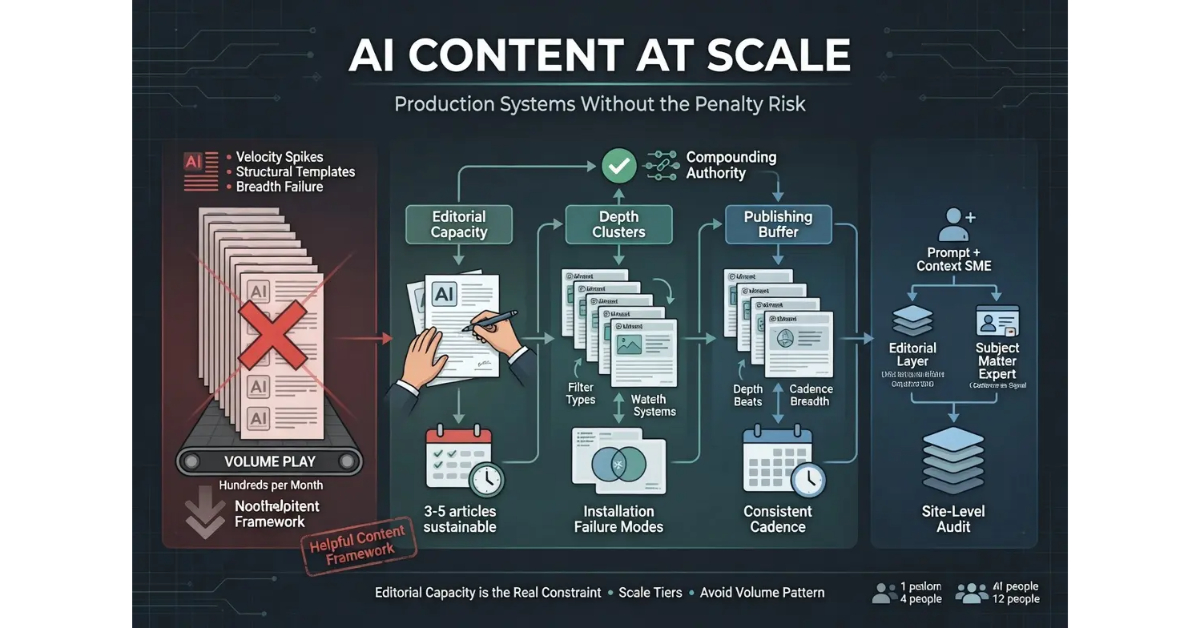
The rule: The constraint on sustainable AI content scale is editorial capacity, not drafting capacity. Operations that scale drafting beyond their editorial capacity have built systems that produce failure mode content at higher volume.
Table of Contents
Why Volume Is the Failure Mode
The first principle of AI content at scale is that volume is the failure mode most operators hit. The AI production model rewards volume because volume is what AI produces cheaply, and operators who optimize for volume produce content patterns that match exactly what the helpful content framework specifically targets. The pattern is detectable, the suppression is real, and the operators who run into it are usually the operators who scaled fastest because they assumed the cheap production cost translated directly to scaled rankings.
The pattern has several recognizable features. Large numbers of articles published in compressed time windows, often dozens per week or hundreds per month. Similar structural features across the published articles because they were produced from similar prompts using similar templates. Similar voice signatures because the editorial layer was thin or absent. Surface-level coverage of broad topical surfaces because the production goal was breadth rather than depth. Author bylines that are generic or absent because the production model has no human author to credit.
The aggregate signal these features produce is the signal Google’s systems have grown most capable of identifying since the helpful content framework was introduced. The aggregate is not always evaluated at the individual article level, where any specific piece might pass quality evaluation. The aggregate is evaluated at the site level, where the patterns compound across all the published articles into a site-wide signal that the systems treat as one piece of evidence about whether the site is producing content for people or for search engines.
The implication for operators is that the volume failure mode is not avoidable through better individual articles. The aggregate signal is what gets evaluated, and even substantively good articles can be suppressed when the surrounding content base exhibits the volume pattern. The fix is not to write better individual articles inside a volume operation. The fix is to change the operational approach to one that does not produce the aggregate pattern.
The shorthand version: volume produces a site-wide pattern that the framework targets regardless of individual article quality. Operators who want to scale content production sustainably need to do it in a way that does not trigger the pattern, which means depth rather than breadth as covered in the next section.
For the broader context on how scale fits into AI content creation strategy, the Pillar guide on AI Content Creation covers the full framework. The sibling articles on How to Use AI to Write SEO Content, AI Content vs Human Content, and the AI Content Editorial Layer cover the other dimensions.
Depth Beats Breadth
The depth approach is the alternative to the volume play, and the difference between the two is operational rather than philosophical. Operators who use AI to produce substantive long-form content on focused topical clusters scale differently than operators who use AI to produce thin coverage across broad topical surfaces. Both approaches involve AI. Both involve scale. The outcomes diverge dramatically because the patterns each approach produces sit on opposite sides of the framework’s evaluation.
The depth approach concentrates content production on focused topical clusters where the operator has genuine expertise and can build substantive coverage. A site covering home improvement might focus on water filtration, with cluster pages on filter types, installation patterns, water quality testing, and the specific failure modes operators encounter in real systems. The depth comes from the operator’s experience with the topic, surfaced through the editorial layer in ways the model alone could not produce.
The breadth approach distributes content production across many topics where the operator may have no particular expertise. The same site might cover home improvement broadly, with thin articles on water filtration, electrical work, plumbing repair, HVAC maintenance, lawn care, and dozens of other categories. The breadth produces volume, but the volume comes at the cost of substantive depth on any individual topic.
The compounding effect of depth is what makes the approach scale sustainably. Each article on water filtration contributes to the site’s topic authority on water filtration. The articles reinforce each other through internal linking, shared expertise signals, and the cumulative depth that signals to Google’s systems the site is a serious source on the topic. The compounding produces a content base that gets stronger over time even as individual article additions slow.
The opposite pattern emerges from breadth. Each thin article on a different topic does not contribute to topic authority on anything because no individual topic accumulates enough depth to demonstrate authority. The articles do not reinforce each other because they are not topically connected in ways that aggregate signals. The content base does not get stronger over time because it never reaches sufficient depth on any topic to signal expertise.
The implication for operators considering scale is that the strategic question is not how many articles to publish but which topics to publish them on. Operators who pick three to five topical clusters and produce substantive depth on each scale sustainably. Operators who pick fifty topics and produce thin coverage on each produce the volume failure mode regardless of how disciplined the individual article production is.
The honest read on depth versus breadth is that depth is harder operationally because it requires operators to commit to topical focus rather than chasing whatever produces the most search traffic in the short term. The commitment is what produces the compounding effect, and operators who treat topical commitment as optional miss the dimension that determines whether scale works.
For more on the broader content production discipline that supports the depth approach, the Content discipline covers the operational architecture.
The Editorial Capacity Constraint
The editorial capacity constraint is the operational reality that determines what scale is actually achievable for a given operation. The constraint is not the drafting layer because AI produces drafts at near-zero marginal cost. The constraint is the editorial layer where human judgment turns drafts into publishable content. The editorial layer scales linearly with content output, which means doubling content output requires roughly doubling editorial capacity.
The capacity question breaks across two dimensions. The first dimension is the time per article that the editorial layer requires. For substantive long-form content the editorial layer typically takes several hours per article when applied with the depth the layer requires. The time decreases as operators build calibration muscle, but does not reduce to zero. The second dimension is the number of articles per week the operator can move through the editorial layer while maintaining the depth.
The honest answer most operators do not want to hear is that one operator running editorial layer at depth on substantive long-form content can typically handle three to five articles per week sustainably. Operators who push past that capacity start cutting corners in the editorial layer, which produces the AI fingerprint output the layer is designed to prevent. The capacity is not a soft constraint that can be pushed through with effort. The capacity is a hard constraint that determines what the operation can produce sustainably.
The implications for scale are direct. An operation with one editor producing three to five articles per week at depth maxes out at roughly two hundred articles per year. An operation with three editors maxes out at roughly six hundred. An operation with ten editors maxes out at roughly two thousand. The math compounds linearly, and the constraint applies at every scale tier.
The temptation operators face is to push the editorial capacity past its sustainable point because the drafting layer can produce more drafts than the editorial layer can handle. The push produces a backlog of drafts that either get published with insufficient editorial work or pile up unused. The first outcome is the failure mode. The second outcome is wasted effort that does not contribute to scale.
The fix is to scale drafting volume to match editorial capacity rather than scaling editorial down to match drafting volume. Operators who let drafting capacity drive the operation produce the volume failure mode. Operators who let editorial capacity drive the operation scale sustainably at whatever pace their editorial bandwidth allows. The constraint is real, and operators who respect it produce content that ranks while operators who try to push past it produce content that gets suppressed.
Publishing Cadence as Signal
The publishing cadence is itself a signal that Google’s systems use to evaluate sites, and the signal aggregates with the other site-level signals to produce the overall pattern that determines whether the framework treats the site as legitimate or as one of the volume-play operations the framework targets.
The pattern that signals legitimate operations is consistent cadence over extended time horizons. Sites that publish on regular schedules, with output that stays relatively constant across weeks and months, produce a cadence signature that matches how editorial operations actually work. The consistency suggests an underlying production process with sustainable inputs, which is what mature publishing operations have and what volume-play operations typically lack.
The pattern that signals volume-play operations is irregular bursts. Sites that publish many articles in compressed time windows, then go quiet for extended periods, then burst again, produce a cadence signature that matches automated production runs rather than editorial operations. The pattern is detectable algorithmically and aggregates with the other volume-play signals into the site-wide pattern that triggers suppression.
The trap operators sometimes fall into is publishing in batches because that is when the AI workflow produced the content. The batches reflect production reality rather than editorial reality, but the publishing pattern that emerges signals the production reality to Google’s systems. The fix is to space out publishing across time even when the content is produced in batches, which means maintaining a publishing buffer that smooths out the production variations into consistent output.
The buffer pattern works like this. Operators produce content at whatever pace the editorial capacity allows, building up a buffer of completed articles ready to publish. The buffer enables consistent publishing on regular schedules even when production is uneven. New content goes into the buffer rather than directly to publish, and publishing draws from the buffer at the consistent cadence the operator has established.
The buffer also serves a secondary purpose: it protects against the days when production stalls. Operators who publish directly from production have nothing to publish on the days production stalls, which produces gaps in the cadence. Operators who publish from a buffer maintain consistency through production variations, which preserves the cadence signal that legitimate operations exhibit.
The honest read on publishing cadence is that it requires operational discipline that operators sometimes find counterintuitive. Producing five articles in one weekend feels productive, but publishing all five that Monday signals volume-play. Spacing the same five articles across a month produces stronger ranking signals than the burst publishing produces, even though the underlying work is identical.
The Scale Tiers
The operational architecture for AI content production differs across scale tiers, and naming the tiers directly clarifies what works at each level. The tiers break across roughly three categories: solo operator scale, small team scale, and full content operation scale. Each tier has different operational patterns and different failure modes.
Solo operator scale is the configuration most AI content operations actually run at, regardless of how operators describe themselves. One person handles drafting, editorial layer, and publishing. The realistic output ceiling is three to five articles per week sustainably, which produces somewhere between one hundred fifty and two hundred fifty articles per year. The solo configuration works well for focused topical operations where the operator has deep expertise in the cluster they are covering.
The failure mode at solo scale is the operator pushing past their own editorial capacity in pursuit of more output. The push produces the AI fingerprint output that triggers suppression, and the suppression affects the entire site rather than just the articles where corners were cut. The fix is honest assessment of what the operator can sustainably produce at depth and willingness to publish at that pace rather than at the pace the drafting layer enables.
Small team scale is the configuration where two to five operators collaborate on content production. The team can specialize, with some operators focused on drafting and others on editorial work. The realistic output ceiling depends on team composition but typically lands between fifteen and forty articles per week. Small team scale works for operations covering multiple topical clusters with depth on each.
The failure mode at small team scale is the editorial bottleneck. Teams that scale drafting capacity faster than editorial capacity produce the same volume-play output as undisciplined solo operators, just at higher throughput. The fix is to make sure editorial capacity scales alongside drafting capacity, which often means hiring editors before adding more drafters.
Full content operation scale is the configuration where five to twenty operators run a substantial content business. The operation has dedicated editorial roles, dedicated drafting roles, dedicated publishing operations, and the management overhead of coordinating across multiple workstreams. The realistic output ceiling is hundreds of articles per month while maintaining editorial discipline. Full operation scale works for businesses where content is the primary product and the business model supports the operational overhead.
The failure mode at full operation scale is the cultural drift toward volume metrics over quality metrics. Larger operations face pressure to demonstrate output, and output is easier to measure than orientation. Teams that drift toward output metrics produce the volume-play output regardless of individual editorial discipline because the operational orientation has shifted. The fix is sustained leadership attention to the orientation question, with output metrics treated as outputs of correct orientation rather than as goals to optimize for directly.
Team Architecture for Larger Operations
The team architecture that supports AI content scale at the small team and full operation tiers has specific operational patterns that distinguish it from generic content team structures. The patterns address the specific failure modes that AI-assisted production introduces, and operations that adopt the patterns scale more sustainably than operations that treat AI content production as identical to traditional content production.
The first architectural pattern is separating the prompt-and-context role from the editorial role. The prompt-and-context role requires the operator’s substantive perspective on the topic and produces the structured briefs that drive drafting. The editorial role requires the operator’s voice calibration, fact-checking discipline, and structural editing. The two roles can be combined for solo operators but should be separated as operations scale because the skills required for each are different and the time required for each does not necessarily scale together.
The second architectural pattern is dedicated subject matter expertise for topical depth. Operations that cover multiple topical clusters benefit from having dedicated SME involvement on each cluster, even when the SME is not doing the drafting or editorial work directly. The SME provides the substantive context for prompts, reviews drafts for accuracy, and adds the experience markers that the cluster requires. SME involvement is what prevents the breadth approach from sliding into the volume-play failure mode.
The third architectural pattern is shared style guides and voice references. Operations producing content under a common brand need consistent voice across the published output, and the consistency is harder to achieve when multiple operators are using AI to produce drafts. The fix is detailed style guides that specify the voice characteristics, sample content that demonstrates the voice in action, and editorial review processes that catch voice drift. The investment in style infrastructure pays back across every article produced.
The fourth architectural pattern is the publishing buffer at the operation level rather than at the individual operator level. Operations that maintain a buffer of completed articles can publish at consistent cadence even when individual operator production varies. The buffer provides operational resilience and preserves the cadence signal that legitimate operations exhibit.
The fifth architectural pattern is regular site-level audits as part of the operational cadence. Larger operations face pattern drift across multiple operators and multiple production cycles, and the drift is not visible at the individual article level. Site-level audits sample across the published content and identify patterns that compound across articles, including structural homogeneity, voice consistency drift, missing experience markers, and other signals that aggregate into the site-wide pattern Google’s systems evaluate.
For the broader credibility infrastructure that supports team-level content operations, the Credibility discipline covers the operational architecture.
What Fails at Scale
The patterns that fail at AI content scale are predictable, and naming them directly is the most efficient way to help operators recognize the failure modes before they hit them. The patterns break across several categories that compound when they appear together.
The first failure pattern is the velocity spike. Operations that publish many articles in compressed time windows produce velocity signatures that mature publishing sites do not exhibit. The signature is detectable, and the suppression that follows is site-wide rather than article-specific. The fix is the publishing buffer covered earlier in this article.
The second failure pattern is the structural template. Operations that use the same prompt template across many articles produce content with identical structural patterns across the site. The pattern is visible to readers within a few articles and is detectable algorithmically across the broader content base. The fix is varied prompt structures and structural editing in the editorial layer.
The third failure pattern is the editorial layer thin-out. Operations that scale drafting capacity beyond editorial capacity produce content with progressively weaker editorial work as the editorial team falls behind. The thin-out happens gradually and is hard to detect from inside the operation, which is why site-level audits are essential. The fix is to scale editorial capacity ahead of drafting capacity rather than behind it.
The fourth failure pattern is the topical breadth without depth. Operations that cover too many topics with thin coverage produce content that does not accumulate topic authority on any subject. The failure is invisible in the short term because individual articles can rank temporarily, but the long-term ranking trajectory flatlines because no topic ever reaches sufficient depth. The fix is topical focus and willingness to commit to clusters even when the commitment forecloses other opportunities.
The fifth failure pattern is the missing author infrastructure. Operations that publish under generic admin accounts or unnamed authors signal that the production layer is not connected to any human expertise. The signal compounds with the other AI content patterns into the site-wide failure signature. The fix is real authorship infrastructure with named authors, surfaced bios, and credential signals where applicable.
The sixth failure pattern is the ignored audit signal. Operations that conduct site-level audits but do not act on the findings end up with the same outcomes as operations that do not audit at all. The audit identifies patterns; the action on the patterns is what produces the correction. Audits without action are theater. The fix is treating audit findings as operational priorities rather than as informational reports.
The seventh failure pattern is the volume-justified-by-data trap. Operations that produce volume content and cite their analytics as evidence the approach works often miss the longer-term trajectory where the volume content underperforms relative to depth content over multi-year horizons. The short-term metrics can favor volume because the volume produces traffic before the suppression patterns aggregate. The longer trajectory shows the cost. The fix is multi-year horizon thinking rather than monthly metrics optimization.
Verdict
AI content at scale is achievable, but the path is more disciplined than most operators initially expect. The constraint on sustainable scale is editorial capacity rather than drafting capacity, and operations that respect the constraint scale sustainably while operations that try to push past it produce the volume failure mode the helpful content framework specifically targets.
The depth approach beats the breadth approach across every measurement frame that matters over multi-year horizons. Operators who concentrate production on focused topical clusters where they have genuine expertise build content bases that compound over time. Operators who distribute production across broad topical surfaces produce content bases that flatline because no individual topic accumulates enough depth to demonstrate authority.
The publishing cadence is itself a signal. Consistent cadence over extended time horizons matches how legitimate publishing operations work. Irregular bursts match how volume-play operations work. The publishing buffer pattern smooths out production variations into consistent output, which preserves the cadence signal regardless of underlying production variability.
The scale tiers from solo operator to full content operation each have distinct operational patterns and distinct failure modes. Solo operators max out around three to five articles per week at depth. Small teams max out at fifteen to forty per week. Full operations can produce hundreds per month while maintaining editorial discipline. Each tier has its own architectural requirements, and each tier fails in different ways when the architecture is wrong.
The failure modes that catch operations are predictable. Velocity spikes, structural templates, editorial thin-out, topical breadth without depth, missing author infrastructure, ignored audit signals, and volume-justified-by-data thinking. Operations that recognize these patterns avoid them. Operations that do not recognize them eventually hit them, and the hit is usually at the scale where recovery is most expensive.
For the broader framework that ties scale together with the rest of the AI content creation discipline, the Pillar guide covers the full system. The sibling article on How to Use AI to Write SEO Content covers the workflow that produces the drafts the editorial layer works on. The article on AI Content vs Human Content covers the framework that explains why orientation determines outcomes regardless of production method. The article on the AI Content Editorial Layer covers the operational discipline that makes editorial capacity the constraint that scale operations have to respect.
Frequently Asked Questions
How many AI-assisted articles can one operator publish per week?
Three to five articles per week sustainably for substantive long-form content with proper editorial layer applied. Operators who push past that capacity start cutting corners in the editorial layer, which produces the AI fingerprint output that triggers suppression. The capacity is a hard constraint, not a soft target.
Why does volume AI content get suppressed?
Volume produces site-wide patterns that the helpful content framework specifically targets. The patterns include velocity spikes, structural homogeneity, voice uniformity, surface coverage of broad topics, and missing experience markers. Google’s systems aggregate these signals at the site level, and the aggregate triggers suppression even when individual articles pass quality evaluation.
Should I publish all my AI content as soon as it is ready?
No. Publishing patterns that match production reality rather than editorial reality signal volume-play to Google’s systems. The fix is the publishing buffer pattern: produce content at whatever pace editorial capacity allows, build a buffer of completed articles, and publish at consistent cadence regardless of production variations.
What is the difference between depth and breadth approaches?
Depth concentrates production on focused topical clusters where the operator has genuine expertise. Breadth distributes production across many topics with thin coverage on each. Depth produces compounding topic authority over time. Breadth produces content that does not accumulate authority on any topic because no individual topic reaches sufficient depth.
How do I know if my AI content operation is at risk?
Run a site-level audit. Sample articles across the site and read them as a reader would. Look for velocity spikes in the publishing history, structural homogeneity across articles, missing first-hand experience markers, surface coverage of topics rather than substantive depth, and missing author infrastructure. Sites that exhibit these patterns are at risk regardless of how disciplined the individual article production feels.
Can I scale AI content if I work alone?
Yes, at solo operator scale, which maxes out around three to five articles per week sustainably. Solo operators who focus on a single topical cluster where they have deep expertise can build substantive content bases over time. The scale is real even though it is smaller than what some operators initially expect.
What does the team architecture for AI content look like?
Separate the prompt-and-context role from the editorial role as operations scale. Maintain dedicated subject matter expertise for topical depth. Invest in shared style guides and voice references for consistency. Maintain a publishing buffer at the operation level. Run regular site-level audits to catch pattern drift across operators and production cycles.
How fast can a content operation safely scale?
Editorial capacity needs to scale ahead of drafting capacity rather than behind it. Operations that hire drafters first and editors later produce the volume failure mode during the gap. Operations that hire editors first and drafters later scale sustainably because the editorial bottleneck is addressed before drafting capacity outruns it.



