AI Content Creation for SEO: The Complete Guide to Using AI Without Getting Penalized

AI Summary
What is AI content creation for SEO? AI content creation is the practice of using large language models to assist with writing content intended to rank in search engines. The framework operates on a single principle: Google evaluates content based on whether it serves people, regardless of how it was produced.
What it is and who it is for: AI content creation matters for any operator publishing content at the volume modern SEO requires. The methodology applies whether AI is doing the drafting, the editing, the outlining, or the entire production cycle, and the questions that determine ranking outcomes are the same regardless of where AI sits in the pipeline.
The rule: Google’s helpful content guidance does not penalize AI content. It penalizes content created primarily for search engines rather than for people, and AI-produced content fails that test more often than human-produced content because the production model rewards volume over substance unless the operator builds discipline against that pull.
Table of Contents
- The Actual Question Google Asks
- How to Use AI to Write SEO Content
- AI Content vs Human Content: The Wrong Frame
- The Editorial Layer That Separates Ranking From Suppressed
- AI Content at Scale Without the Penalty Risk
- The Failure Modes That Trigger Suppression
- What Changed in 2026 and What Did Not
- Verdict
The Actual Question Google Asks
The SEO industry has spent four years arguing about whether AI content is allowed, whether it gets penalized, whether Google can detect it, and whether operators should disclose it. The arguments persist because they are entertaining and produce engagement. The arguments are also irrelevant to whether any specific piece of AI-assisted content ranks, because Google’s actual position has been consistent since the question first emerged in 2022.
The position lives in Google’s official guidance from February 2023 and has been reinforced in every helpful content update since. Google does not penalize content because it was produced with AI. Google penalizes content that was produced primarily for search engines rather than for people. The two frames sound similar but produce very different operational implications, and operators who confuse them end up with the wrong mental model for the work.
The shift Google has been driving over the past five years is not about AI specifically. It is about the longer-running effort to move ranking signals away from surface features that can be gamed and toward substantive quality that cannot. AI content sits inside that broader trajectory rather than as a separate consideration. The framework was built before AI scaled, applies to AI without modification, and will continue applying as AI capabilities continue evolving.
The shorthand version: Google asks whether the content serves the reader. The answer determines ranking outcomes. The production method is irrelevant except insofar as production method affects whether the content actually serves readers. AI affects this differently than human writing does, but the question being asked is the same.
The deeper context for how this question fits into the broader content production discipline lives at the Content discipline page. The infrastructure that supports the credibility judgments Google’s systems make about AI content lives at the Credibility discipline page.
How to Use AI to Write SEO Content
The practical question most operators want answered is the workflow. What does it actually look like to use AI for content production in a way that produces ranking outcomes rather than algorithmic suppression. The honest answer is that the workflow is more disciplined than most operators expect, and the discipline is exactly what separates AI content that ranks from AI content that does not.
The first principle is that AI is a drafting partner, not an autopilot. Operators who feed a topic to a model and publish whatever comes out have built a system that produces failure mode content at scale. The model is trained to produce plausible-sounding text on any topic, and plausible-sounding text is not the same as text that demonstrates substantive knowledge of the topic. The output reads competent and contains no actual signal of expertise, experience, or first-hand contact with the subject. Google’s systems have grown capable of identifying this pattern and suppress it accordingly.
The second principle is that the human editorial layer is not optional. The operator brings the things AI cannot bring. The first-hand experience markers, the texture of having actually done the thing, the calibrated confidence that comes from being wrong and corrected by reality, the engagement with edge cases the model would not know to surface. The editorial layer is where these get added, and the layer is not negotiable for content that needs to rank.
The third principle is that the prompt structure matters. Operators who give the model substantive context about the operator’s actual perspective, the audience the content serves, the angle the piece is taking, and the constraints the writing has to honor produce dramatically better drafts than operators who give the model a topic and walk away. The model can do remarkable work when it understands what is actually being asked. The model can do generic work when the prompt is generic, which is the default failure mode.
The fourth principle is that the workflow is iterative. The first draft is the starting point, not the finished product. The work of getting from draft to publishable involves rewriting passages where the model defaulted to generic framing, adding the experience markers the model could not generate, fact-checking the claims the model made with confidence regardless of whether they were accurate, and calibrating voice to match the operator’s actual writing rather than the model’s default cadence.
For the deeper operational treatment of the AI writing workflow, the prompt patterns that produce substantive drafts, the editorial discipline that turns drafts into publishable articles, and the common failure modes operators encounter at the workflow level, the tier article on How to Use AI to Write SEO Content covers the full operational guide.
AI Content vs Human Content: The Wrong Frame
The question operators most often ask is whether AI content ranks as well as human content. The question is the wrong frame because it assumes the AI versus human distinction is the dimension that determines ranking outcomes. The actual dimension is whether the content serves readers, and both AI-produced and human-produced content can succeed or fail on that dimension.
The framing that maps onto how Google’s systems actually evaluate content is closer to the helpful content guidance language. Content created primarily for people that happens to also rank is the configuration that scales. Content created primarily for search engines that happens to use AI or human writing is the configuration that fails. The production method is downstream of the orientation, not upstream of it.
The data that operators sometimes cite about AI content underperforming is real, but the explanation is not what the data suggests on the surface. AI content underperforms on average because AI content production at scale has been dominated by operators using AI for the volume play that the helpful content guidance specifically targets. The underperformance is correlation with the volume play, not causation from the AI production. AI content produced with editorial discipline performs comparably to human content produced with the same discipline, which is what the actual ranking data shows when the variables are controlled.
The reverse is also worth naming. Human content is not automatically helpful content. A human writer producing thin, surface-level coverage of topics they have no genuine expertise in produces content that fails the helpful content framework regardless of being human-authored. The dimension that matters is the substantive quality of the work, not the species of the producer.
One detail worth flagging directly. Google’s systems are not particularly invested in distinguishing AI content from human content as a primary signal. The systems are invested in distinguishing helpful content from content created for search engines, and the production method is a weak signal compared to the substantive quality signals that actually drive the evaluation. Operators who optimize for hiding AI involvement rather than for producing helpful content have the priorities backwards.
For the deeper treatment of how Google’s systems actually evaluate content quality, the helpful content guidance in detail, why the AI versus human binary is the wrong frame, and what the empirical data shows when the variables are controlled, the tier article on AI Content vs Human Content covers the full analysis.
The Editorial Layer That Separates Ranking From Suppressed
The editorial layer is the operational discipline that turns AI drafts into publishable articles. The work is more substantial than most operators expect when they first start working with AI for content production, and the depth of the editorial work is exactly what separates AI content that ranks from AI content that does not.
The first dimension of the editorial layer is fact-checking. Models confidently generate claims that range from accurate to fabricated, and the confidence in the writing is uncorrelated with the accuracy of the underlying facts. Operators who publish AI drafts without fact-checking accumulate inaccuracy across their content base, and the inaccuracy degrades the site’s Trust signal over time. The editorial layer catches the fabrications, verifies the citations, and ensures the claims the article makes can actually be supported.
The second dimension is voice calibration. Models default to a particular cadence, vocabulary, and structural pattern that has become recognizable as AI output. Operators who publish drafts in the default voice produce content that reads as AI-generated regardless of whether the topic coverage is substantive. The editorial layer recalibrates the voice to match the operator’s actual writing pattern, which involves restructuring sentences, swapping default phrasings for the operator’s natural language, and breaking the rhythmic patterns that mark generic AI output.
The third dimension is adding first-hand experience markers. Models cannot produce authentic experience markers because models do not have first-hand experience with the topics they write about. Operators bring those markers from their actual contact with the subject. Photographs of products being tested. Anecdotes that include details only someone present would include. Hedging that reflects the operator’s actual confidence level rather than the confidence the writing position implies. The editorial layer is where these markers get added, and content without them reads as the generic third-person knowledge it actually is.
The fourth dimension is structural editing. Models produce drafts that follow predictable structural patterns. Generic opening framings. Listicle-style enumeration when prose would serve better. Conclusions that summarize what was already said rather than offering synthesis. The editorial layer restructures the piece to match how the operator would have written it if working without AI assistance, which usually involves substantial cuts, reorganization, and the addition of structural moves the model would not have generated.
For the deeper operational treatment of the editorial layer, the fact-checking discipline, the voice calibration patterns, the experience marker integration, and the structural editing patterns that turn AI drafts into ranking content, the tier article on the AI Content Editorial Layer covers the full operational guide.
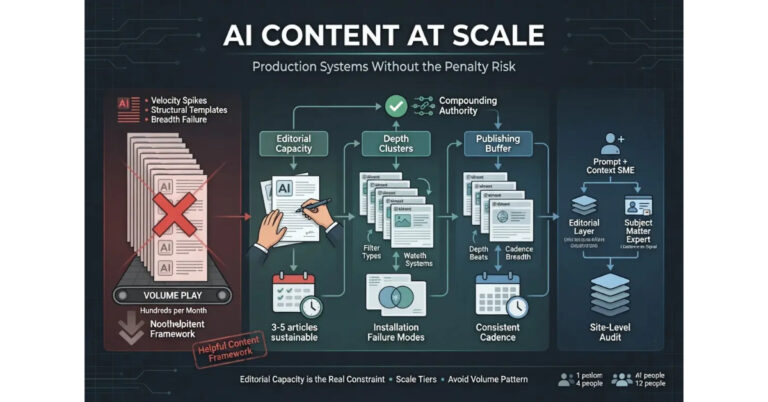
AI Content at Scale Without the Penalty Risk
The question every founder eventually asks but is sometimes hesitant to surface directly is how to scale AI-assisted content production without triggering algorithmic suppression. The question is real, the operational answer exists, and the answer is more disciplined than most operators initially want it to be.
The first principle of scaling is that volume is the failure mode most operators hit. The AI production model rewards volume because volume is what AI produces cheaply, and operators who optimize for volume produce content patterns that match what the helpful content guidance specifically targets. The pattern of large numbers of articles published in compressed time windows, with similar structural features, similar voice signatures, and surface-level coverage of broad topics, is the pattern Google’s systems have grown most capable of identifying. Sites that exhibit the pattern experience suppression that may not register as a discrete penalty but produces ongoing ranking caps the operator cannot identify without auditing the production approach.
The second principle is that scale is achievable through depth rather than through breadth. Operators who use AI to produce substantive long-form content on focused topical clusters scale differently than operators who use AI to produce thin coverage across broad topical surfaces. The depth approach produces fewer articles in the short term but produces a content base that compounds over time because each article contributes to topic authority on a focused subject. The breadth approach produces more articles in the short term but produces a content base that fails to compound because no individual topic accumulates enough depth to demonstrate authority.
The third principle is that the human editorial layer scales linearly with content output. Operators who try to scale AI production without scaling the editorial layer end up with content that exhibits AI fingerprints across the site, and the fingerprints aggregate into a site-wide signal that triggers suppression. The honest answer about scale is that it is constrained by editorial capacity, and operators who scale AI drafting beyond their editorial capacity have built a system that produces failure mode content at higher volume.
The fourth principle is that the publishing cadence matters. Sites that publish in irregular bursts, particularly bursts where many articles appear within compressed time windows, signal patterns that mature authoritative sites do not exhibit. Sites that publish on consistent cadences over extended time horizons signal patterns that match how editorial operations actually work. The cadence is itself a signal, and operators who publish in batches because that is when the AI workflow produced the content end up signaling production patterns rather than editorial patterns.
For the deeper operational treatment of how to scale AI content production without triggering suppression, the production architectures that work at different scale tiers, the editorial capacity constraints, and the publishing cadence patterns that match what mature sites exhibit, the tier article on AI Content at Scale covers the full operational guide.
The Failure Modes That Trigger Suppression
The failure modes that produce algorithmic suppression on AI content are predictable, and identifying them is the most direct way operators can audit their own work to determine whether the production approach is sustainable. The failure modes break across several categories that compound when they appear together.
The first failure mode is the volume signal. Sites that publish large numbers of articles in compressed time windows produce velocity patterns that mature authoritative sites do not exhibit. The pattern is detectable algorithmically and triggers suppression even when individual articles pass quality evaluation, because the aggregate signal of the site is what gets evaluated rather than just the individual pieces.
The second failure mode is the structural homogeneity signal. Sites that publish many articles with the same opening framings, the same heading patterns, the same paragraph rhythm, and the same structural moves signal that the production process is templated rather than editorial. The homogeneity is what AI production tends to produce when the editorial layer is thin or absent, and the signal aggregates across the site into a site-wide pattern that triggers suppression.
The third failure mode is the surface-coverage signal. Sites that publish articles which cover topics at surface depth without engaging with edge cases, without surfacing the why behind the what, without demonstrating working knowledge of the subject, signal that the content was produced by a process that does not have access to the underlying expertise. The signal aggregates into the site-wide pattern that the helpful content guidance specifically targets.
The fourth failure mode is the missing experience signal. Sites that publish articles which never include first-hand markers, never reference actual encounters with the subject matter, never include the texture of having lived through the topic, signal that the content was produced by a process that has no first-hand experience to draw on. The signal is the inverse of the Experience signal in the E-E-A-T framework, and its absence is itself diagnostic.
The fifth failure mode is the credential gap. Sites that publish AI-assisted content under generic byline accounts, without surfaced author bios, without verifiable credentials for the topics being covered, signal that the content production layer is not connected to any human expertise. The signal compounds with the surface-coverage and missing-experience patterns, and the combination is the configuration that the helpful content guidance specifically targets.
The audit pattern that catches these failure modes is the periodic review of the site’s overall content profile. Sample articles across the site. Read them as a reader would. Identify which failure modes are present in the aggregate signal. Address the patterns that compound across multiple articles rather than just the individual issues at the article level. The audit discipline is part of the broader content maintenance work that healthy operations incorporate into their ongoing process.
What Changed in 2026 and What Did Not
The AI content landscape in 2026 looks substantially different from the landscape in 2022 when the question first emerged, and the differences are worth naming directly because they shape what operators should focus on. The differences also clarify what has not changed, which is most of what actually matters.
What changed: the model capabilities. Models in 2026 produce drafts that read more naturally, follow more complex instructions, and require less manual restructuring than models in 2022. The capability improvement reduces the time-cost of the editorial layer for operators who use AI well, but does not eliminate the need for the layer. The improved capabilities produce better starting drafts, not finished products.
What changed: the volume of AI-produced content on the web. Estimates vary, but the share of new web content produced with AI assistance has grown substantially since 2022, and the share continues growing. The volume change has produced a market saturation effect where operators who relied on AI volume as a competitive advantage have lost that advantage as the approach has commodified.
What changed: Google’s detection capabilities. The systems have grown more sophisticated at identifying AI production patterns, content created for search engines rather than people, and the aggregate site-level signals that mark mass production approaches. The improvements operate at the algorithmic level continuously rather than through discrete update cycles, which means sites that exhibit the patterns experience ongoing suppression rather than discrete penalty events.
What did not change: the helpful content framework. The guidance Google published in 2022 still operates in 2026. The framing of “created for people first” still applies. The questions about whether content serves readers, whether expertise is demonstrated, whether the site provides original value beyond what aggregators offer, are still the questions that determine ranking outcomes.
What did not change: the basic operational answer. AI is a drafting partner. The editorial layer is non-negotiable. The depth approach scales better than the breadth approach. The publishing cadence matters. The credentialing layer matters. The questions operators should be asking are the same questions operators should have been asking in 2022, and operators who got this right four years ago are mostly still getting it right today.
The honest read on the 2026 landscape is that the operators who treated AI as a productivity tool inside disciplined editorial workflows have continued to scale their content operations successfully. The operators who treated AI as a way to circumvent the editorial workflow have continued to experience the suppression patterns the helpful content guidance was designed to produce. The two trajectories have diverged further over the past four years, and the divergence will likely continue.
Verdict
AI content creation for SEO is not the binary the industry treats it as. Google’s helpful content guidance does not penalize content because it was produced with AI assistance. The framework penalizes content created primarily for search engines rather than for people, and AI-produced content fails that test more often than human-produced content because the production model rewards volume over substance unless the operator builds discipline against that pull.
The operational answer breaks across four areas. Use AI as a drafting partner rather than as autopilot, with prompt structures that give the model substantive context about the operator’s actual perspective. Build the editorial layer that turns drafts into publishable content through fact-checking, voice calibration, experience marker integration, and structural editing. Frame the work in helpful content terms rather than in AI versus human terms because the framing operators use shapes the configuration they produce. Scale through depth rather than through breadth, with editorial capacity scaling linearly alongside content output.
The failure modes that trigger suppression are predictable. Volume signals, structural homogeneity, surface coverage, missing experience markers, and credential gaps. Sites that exhibit these patterns experience ongoing ranking caps that may not register as discrete penalties but produce the suppression that the helpful content framework was designed to produce. The audit discipline that catches these patterns is part of the broader content maintenance work that healthy operations incorporate into their process.
The 2026 landscape has shifted in important ways. Model capabilities are higher. Web volume of AI content is higher. Google’s detection sophistication is higher. The framework Google uses to evaluate content has not changed, and the operators who got the framework right four years ago are mostly still getting it right today.
The deeper treatment of each dimension lives in the four sibling articles. The article on How to Use AI to Write SEO Content That Ranks covers the practical workflow. The article on AI Content vs Human Content covers what Google actually cares about and why the AI versus human binary is the wrong frame. The article on the AI Content Editorial Layer covers the operational discipline that separates ranking content from suppressed content. The article on AI Content at Scale covers production systems that work without triggering the penalty risk most operators eventually hit.
Frequently Asked Questions
Does Google penalize AI content?
No. Google’s official position since February 2023 is that AI content is not penalized for being AI-produced. The helpful content guidance penalizes content created primarily for search engines rather than for people, and the production method is irrelevant to that evaluation except insofar as it affects whether the content actually serves readers.
Can Google detect AI content?
Google’s systems can identify patterns associated with mass-produced AI content, particularly when those patterns aggregate at the site level. The detection is not focused on individual articles in isolation but on the aggregate signals that mark content created for search engines rather than for people. Operators who produce AI-assisted content with disciplined editorial workflows do not typically register as problematic on these signals.
Should I disclose that content was written with AI?
Google does not require disclosure of AI involvement. Some industries and contexts have separate disclosure requirements that may apply for other reasons, including FTC guidelines for paid content and platform-specific rules. The decision to disclose is not driven by Google’s framework, which is focused on whether the content serves readers regardless of how it was produced.
What is the helpful content framework?
The helpful content framework is Google’s guidance that content should be created primarily for people rather than for search engines. The framework asks whether the content provides original value, demonstrates expertise, serves the reader’s actual needs, and goes beyond what aggregators or surface-level coverage offers. The framework applies to all content regardless of production method.
Can AI-assisted content rank in competitive niches?
Yes, when the editorial layer is substantial enough to produce content that demonstrates the expertise, experience, and substantive depth competitive niches require. The constraint is not the AI involvement but the depth of the editorial work that turns drafts into publishable content. AI-assisted content with disciplined editorial workflows performs comparably to human content with the same discipline.
How do I avoid the AI content penalty?
The approach is to avoid the failure modes that trigger suppression rather than to hide AI involvement. The failure modes include volume signals from compressed publishing windows, structural homogeneity across the site, surface coverage of topics without engaging with depth, missing first-hand experience markers, and credential gaps. Sites that address these patterns through editorial discipline produce content that ranks regardless of AI involvement in the production process.
What is the right way to use AI for SEO content?
AI is a drafting partner inside a disciplined editorial workflow. Operators provide substantive context about their perspective, the audience, the angle, and the constraints. The model produces drafts. Operators add the editorial layer that includes fact-checking, voice calibration, first-hand experience markers, and structural editing. The finished article reflects the operator’s actual perspective and substantive knowledge, with AI handling the drafting workload that the operator would otherwise carry.
How does AI content compare to human content for SEO?
The AI versus human distinction is the wrong frame. The dimension that determines ranking outcomes is whether the content serves readers, and both AI-produced and human-produced content can succeed or fail on that dimension. AI content produced with editorial discipline performs comparably to human content with the same discipline. Both fail when produced without discipline. The production method is downstream of the orientation rather than upstream of it.